
А. В. Брешенков Проектирование баз данных на основе информации табличного вида Допущено в качестве учебного пособия для студентов высших учебных заведений, обучающихся по направлению подготовки диплом
| Вид материала | Диплом |
Содержание4.2.1. Модель информации табличного вида 4.2.2. Модель реляционной таблицы |
- Учебное пособие Допущено Министерством образования Российской Федерации в качестве, 2582.59kb.
- Д. В. Андреев Программирование микроконтроллеров mcs-51, 2064.3kb.
- И. В. Борискина, А. А. Плотников, А. В. Захаров проектирование современных оконных, 1699.55kb.
- «История нового времени», 4001.1kb.
- Учебное пособие. 3-е изд., испр и доп, 125.38kb.
- М. В. Ломоносова Хрестоматия по истории государства и права зарубежных стран, 11295.75kb.
- В. В. Крупица Личность Коллектив Стиль отношений (социально-психологический аспект), 4876.34kb.
- И. М. Синяева, В. М. Маслова, В. В. Синяев сфера, 5230.77kb.
- И. К. Корнеев информационная безопасность и защита информации учебное пособие, 7667.6kb.
- Курслекций допущено умо по образованию в области социальной работы в качестве учебного, 2178.14kb.
4.2. Модели информации табличного вида и реляционных таблиц.
4.2.1. Модель информации табличного вида
Данные табличного вида (DT) представляются множеством DT = {Z, D}, где Z – множество заголовков, D - множество данных.
Z = {
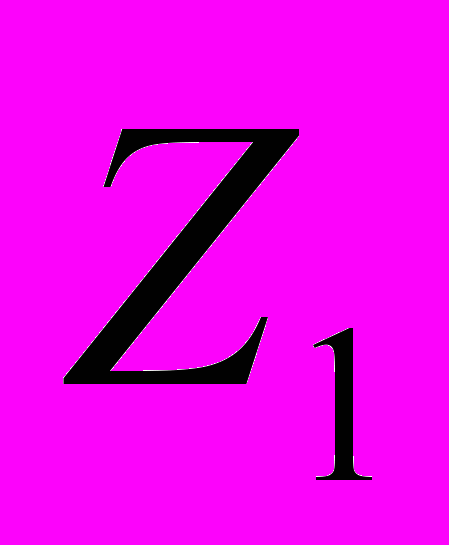 ,…,
,…,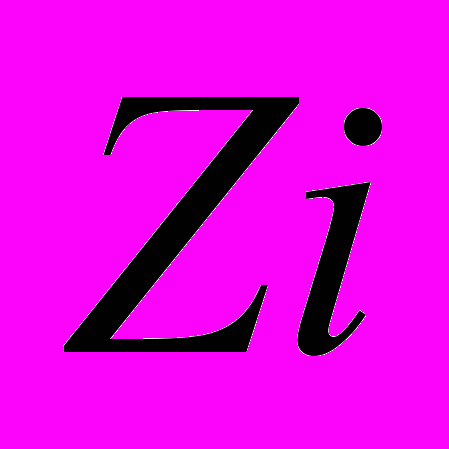 ,…,
,…,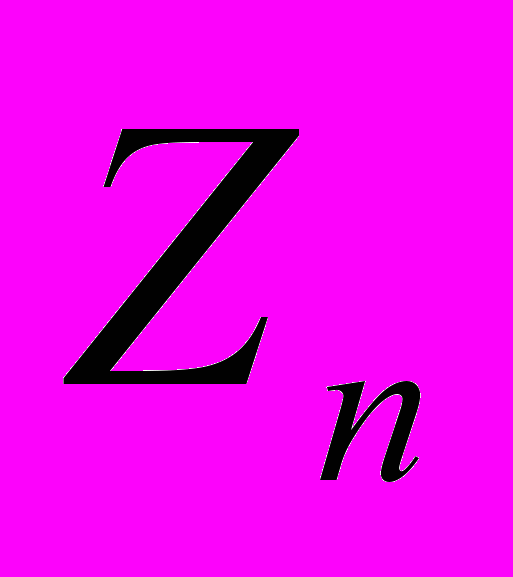 }, i = 1,n; n>=1, где n - степень множества заголовков.
}, i = 1,n; n>=1, где n - степень множества заголовков. Допустима ситуация, когда
= 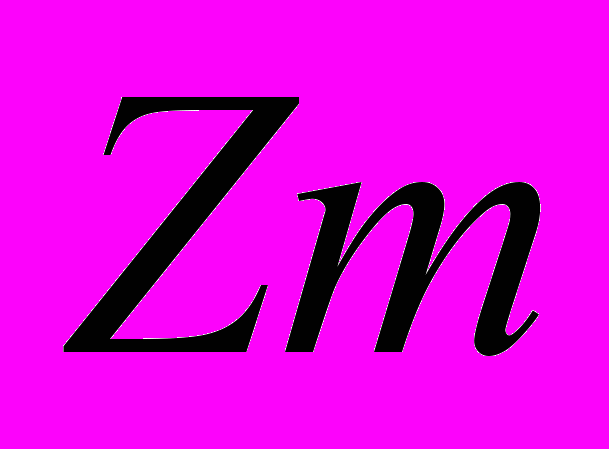 . i = 1,n ; m = 1,n; i ≠ m , где n – степень множества заголовков, т.е. возможно полное совпадение заголовков.
. i = 1,n ; m = 1,n; i ≠ m , где n – степень множества заголовков, т.е. возможно полное совпадение заголовков.В данных табличного вида возможны подзаголовки 1-го уровня, что формально выглядит следующим образом.
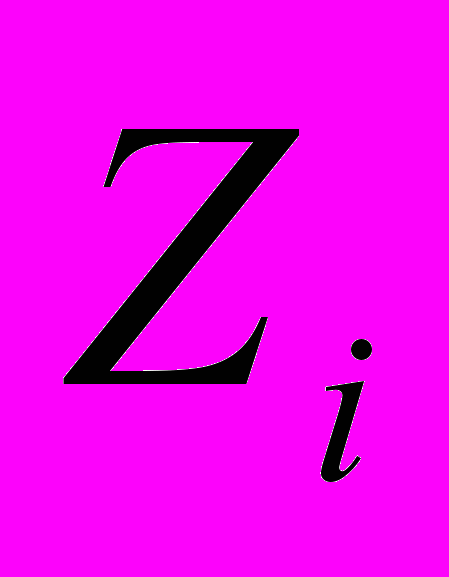 = {P
= {P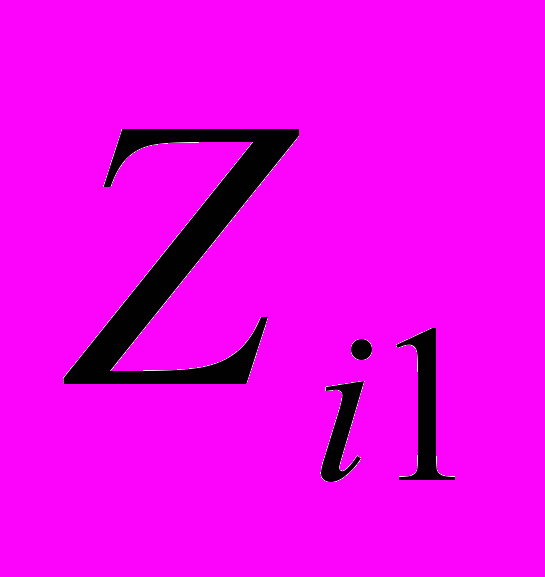 ,…,P
,…,P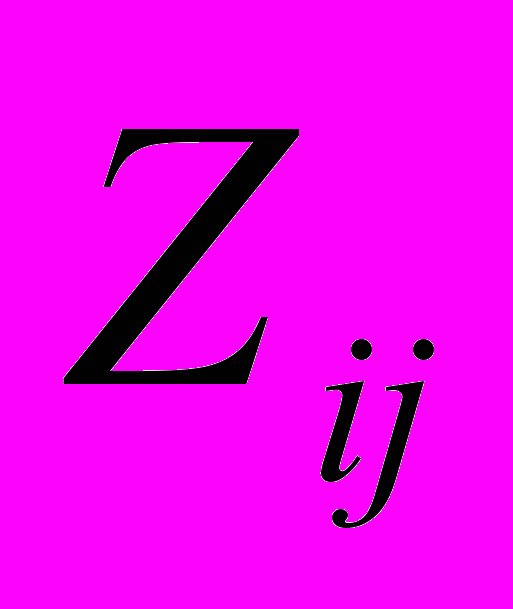 ,…,P
,…,P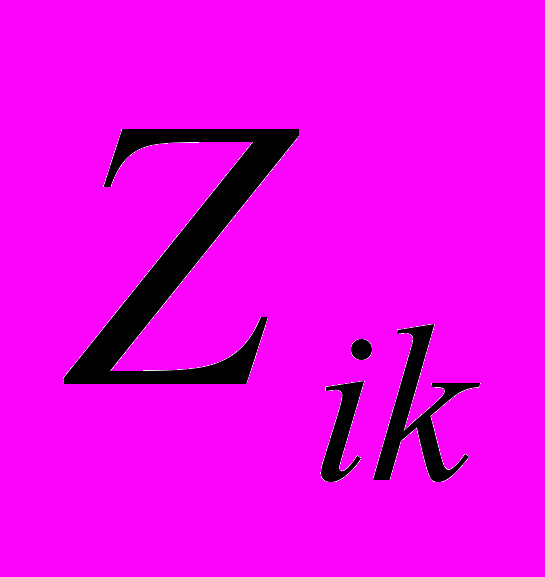 }, j = 1,k; k >=2, где k - степень множества подзаголовков i-го заголовка (1).
}, j = 1,k; k >=2, где k - степень множества подзаголовков i-го заголовка (1).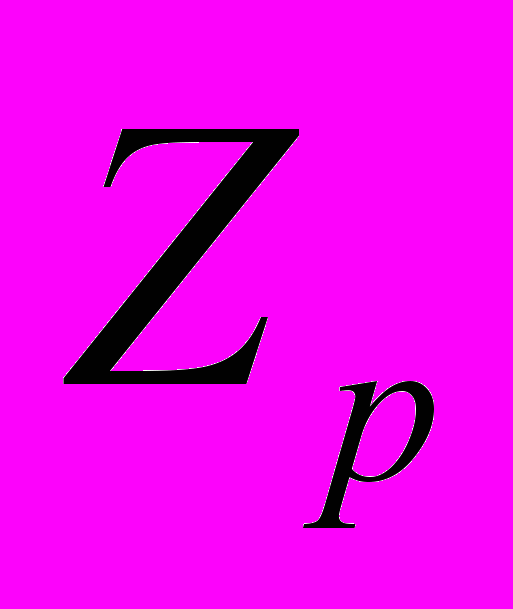 = {P
= {P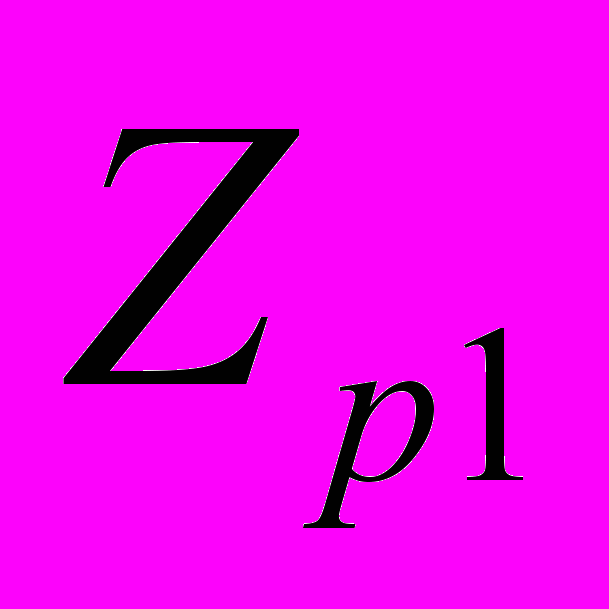 ,…,P
,…,P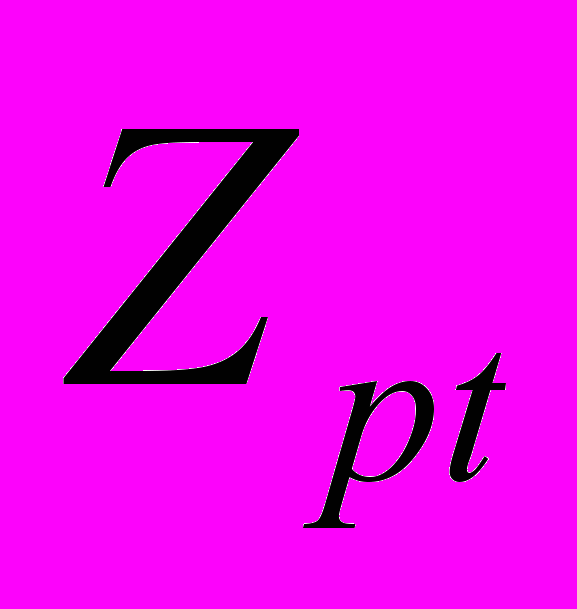 ,…,P
,…,P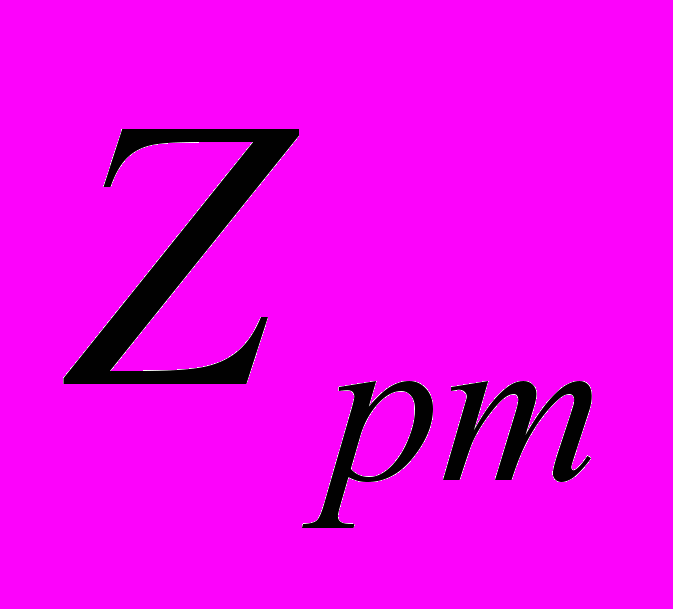 }, t = 1,m; m >=2, где m - степень множества подзаголовков p-го заголовка (2).
}, t = 1,m; m >=2, где m - степень множества подзаголовков p-го заголовка (2).Допустима ситуация, когда P
= P (3).В данных табличного вида возможны подзаголовки 2-го уровня, что формально выглядит следующим образом.
P
= {PP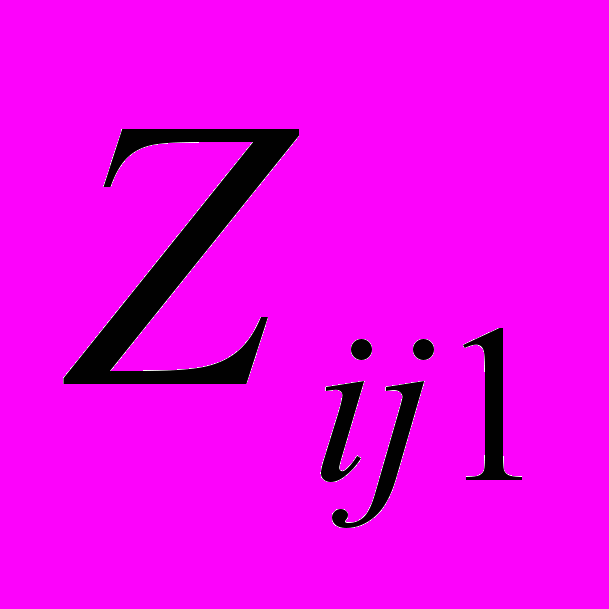 ,…,PP
,…,PP ,…,PP
,…,PP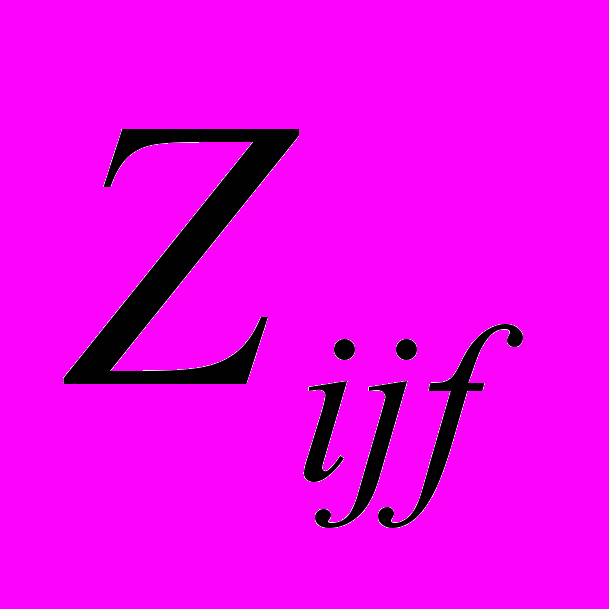 }, m = 1,f; f >= 2, где f - степень множества подзаголовков 2-го уровня ij-го подзаголовка 1-го уровня (4).
}, m = 1,f; f >= 2, где f - степень множества подзаголовков 2-го уровня ij-го подзаголовка 1-го уровня (4). P
= {PP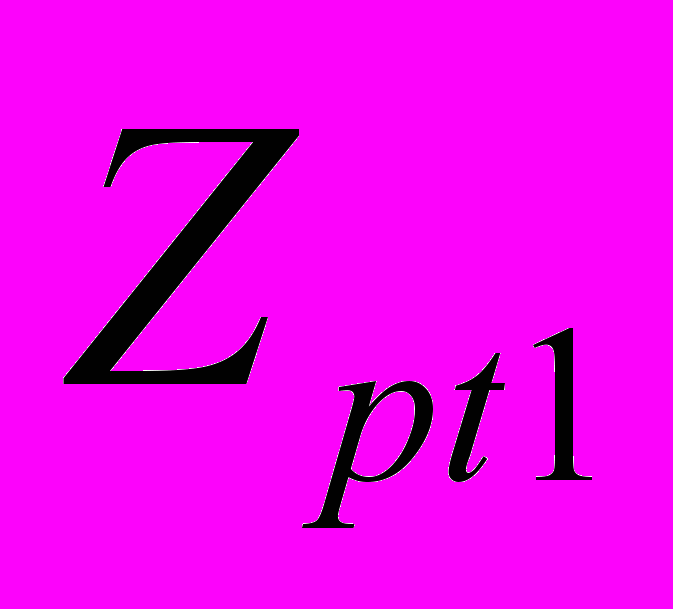 ,…,PP
,…,PP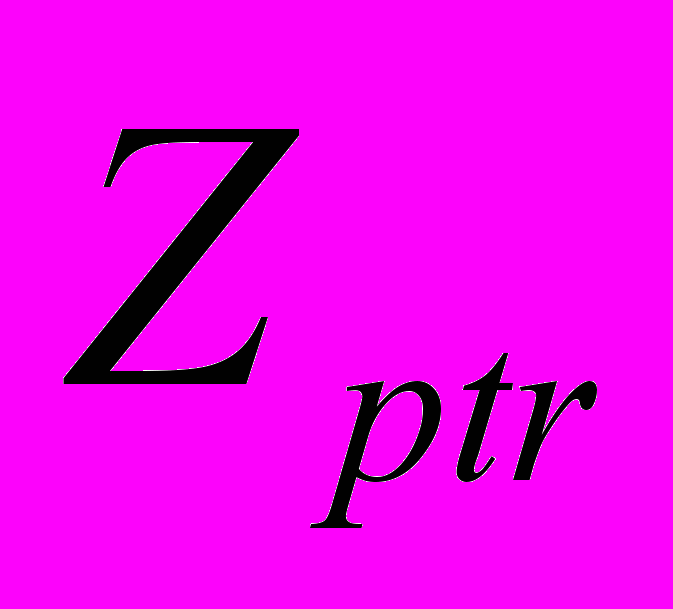 ,…,PP
,…,PP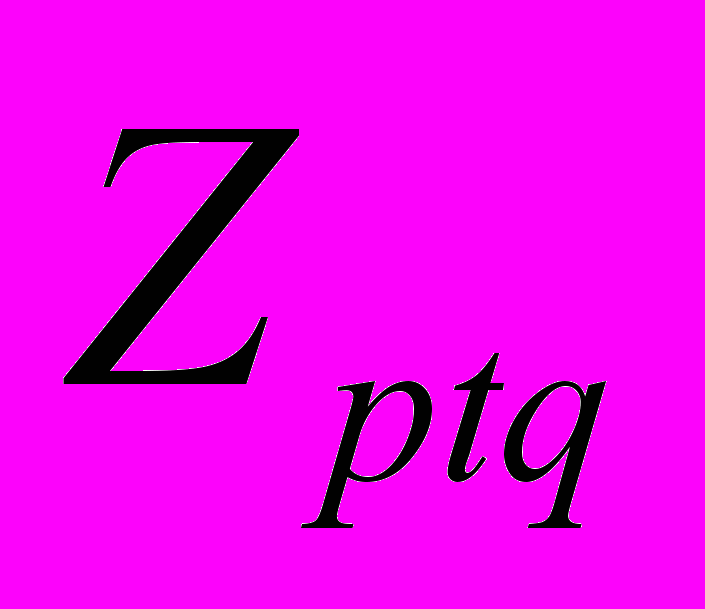 }, r = 1,q; q >= 2, где q - степень множества подзаголовков 2-го уровня pt-го подзаголовка 1-го уровня (5).
}, r = 1,q; q >= 2, где q - степень множества подзаголовков 2-го уровня pt-го подзаголовка 1-го уровня (5).Допустима ситуация, когда PP
= PP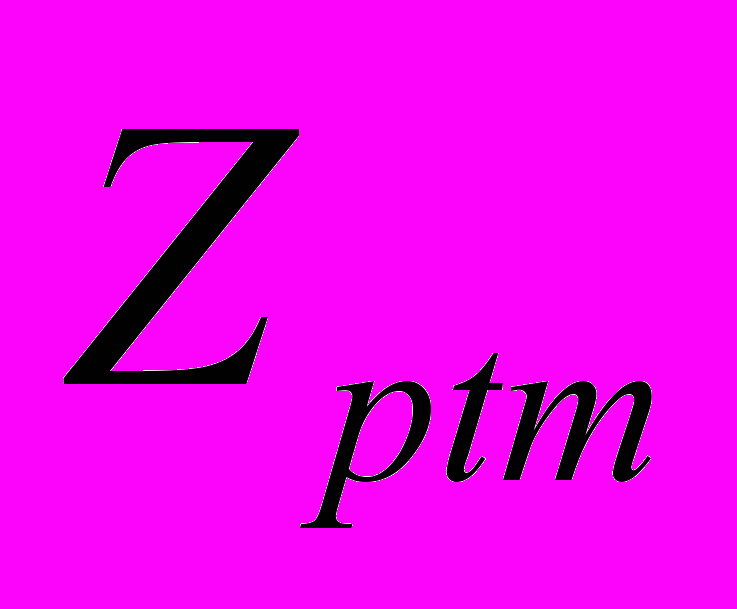 (6).
(6). Теоретически в данных табличного вида может быть больше уровней подзаголовков. Однако, как показывают экспертные оценки реальных табличных данных, обычно имеет место не более 2-х уровней подзаголовков. В связи с этим модель заголовков ограничим 3-мя уровнями.
На рис. 4.2.1 приведен реальный пример с подзаголовками.
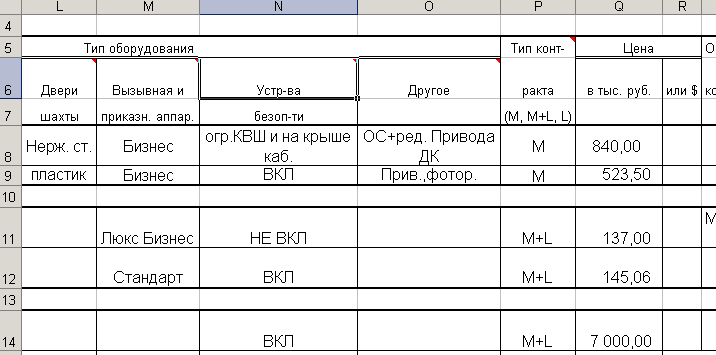
Рис. 4.2.1. Пример с подзаголовками
Здесь заголовок ”Тип оборудования” включает в себя 4-е подзаголовка, заголовок “Цена” включает в себя 2-а подзаголовка.
D = {SD, Z}, где SD – множество строк данных (7).
Такого рода представление D допускает наличие нескольких заголовков и подзаголовков 1-го и 2-го уровней, расположенных в области данных. В том числе допускается наличие заголовков и подзаголовков, расположенных до, после и между строк данных. На рис. 4.2.2 приведен реальный пример с заголовками внутри области данных. Таковыми являются строки 10 и 13.
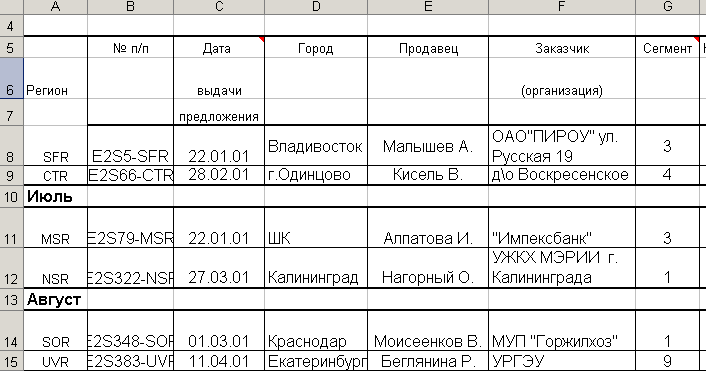
Рис. 4.2.2. Пример с заголовками внутри области данных
SD = {SD1,…,SDi…,SDn}, i = 1,n; n >> 1, где n - мощность множества строк данных.
SDi = {EDi1...,EDij,…,EDik}, j = 1,k; k >= 1, где k - степень множества элементов данных i-ой строки данных; EDij – элемент данных.
Для информации табличного вида должно выполняться следующее правило:
(
 ED) ( SD
ED) ( SD ED) ((
ED) (( z (Z z) (z
z (Z z) (z ED)) V ((PZ)) (z PZ) (PZ ED) V ((PPZ)) (PZ PPZ) (PPZ ED)
ED)) V ((PZ)) (z PZ) (PZ ED) V ((PPZ)) (PZ PPZ) (PPZ ED)Т.е. каждому элементу данных соответствует заголовок или подзаголовок 1-го или 2-го уровней.
(
ED) (SD ED ) (( TED (ED TED)), где TED = string V integer V datetimeТ.е. каждому элементу данных соответствует определенный тип данных.
В общем случае:
TED11≠,…,≠TEDi1≠,…,≠TEDn1
… … … … … … … … … … …
TED1j≠,…,≠TEDij≠,…,≠TEDnj
… … … … … … … … … … …
TED1k≠,…,≠TEDik≠,…,≠TEDnk, i = 1,n; n>>1; j = 1,k; k >= 1,
где n - мощность множества строк данных, k - степень множества элементов i-ой строки данных; Другими словами, значения типов данных одного столбца могут не совпадать.
Допустима ситуация, когда SDi = SDj , i = 1,n ; j=1,n; i≠j , где n – мощность множества данных, т.е. возможно полное совпадение строк данных.
4.2.2. Модель реляционной таблицы
Реляционная таблица (RT) представляется множеством RT = {Z, D}, где Z – множество заголовков, D - множество данных.
Z = {
,…,,…,}, i = 1,n; n>=1, где n - степень множества заголовков. Должно быть обеспечено условие
≠ , i = 1,n ; m = 1,n; i ≠ m (8), где n – степень множества заголовков, т.е. недопустимо совпадение заголовков. D = {SD} (9), где SD – множество строк данных.
SD = {SD1,…,SDi…,SDn}, i = 1,n; n >> 1, где n - мощность множества строк данных.
SDi = {EDi1...,EDij,…,EDik}, j = 1,k; k >= 1, где k - степень множества i-ой строки данных; EDij – элемент данных.
Недопустима ситуация, когда внутри таблицы данных могут встретиться заголовки, т.е. должно выполнятся условие:
SDi ≠
 , i = 1,n; n >> 1; j = 1,k; k >= 1 (10), где
, i = 1,n; n >> 1; j = 1,k; k >= 1 (10), где n - мощность множества строк данных;
k - степень множества заголовков.
Для реляционных таблиц выполняется правило:
(
ED)(SD ED) ((z(Z z) (z ED)Т.е. каждому элементу данных соответствует только один заголовок.
(
ED) (ED SD ) (( TED (ED TED)), где TED = string V integer V datetime V real V logical
Т.е. каждому элементу данных соответствует определенный тип данных.
В реляционных таблицах обязательно выполнение следующего требования:
TED11=,…,=TE Di1=,…,=TE Dn1
… … … … … … … … … … …
TE D1j=,…,=TE Dij=,…,=TE Dnj
… … … … … … … … … … …
TE D1k=,…,=TE Dik =,…,=TE Dnk, i = 1,n; n>>1; j = 1,k; k >= 1,
где n - мощность множества строк данных, k - степень множества i-ой строки данных; EDij – элемент данных. Другими словами, значения типов данных одного столбца должны совпадать.
Недопустима ситуация, когда SDi = S Dj , i = 1,n ; j=1,n; i≠j , где n – мощность множества данных.
Т.е. невозможно полное совпадение строк данных.
Несмотря на некоторое сходство модели данных табличного вида и модели реляционной таблицы, в них имеются существенные различия. Сравнивая условия (1-7) в модели данных табличного вида и условия (9-10) в модели реляционной таблицы, нетрудно заметить, что эти условия не совпадают. В связи с этим для преобразования данных табличного вида в реляционные таблицы необходимо как минимум добиться выполнения условий (9 -10).
При этом целевая функция для условий (1-4) выглядит следующим образом:
((min(j)
 …min(i)…min(t))………
…min(i)…min(t))………((min(m)
…min(k)…min(r)), гдеj - количество подзаголовков 1-го уровня 1-го заголовка;
t - количество подзаголовков 1-го уровня последнего заголовка;
m - количество подзаголовков 2-го уровня первого подзаголовка заголовка 1-го уровня;
r - количество подзаголовков 2-го уровня последнего подзаголовка заголовка 1-го уровня.
Другими словами число подзаголовков 1-го и 2-го уровней нужно минимизировать, а точнее совсем от них избавиться. Таким образом, будет реализована 1-ая нормальная форма - атрибуты реляционной таблицы должны быть атомарными.