
Функциональные возможности моделей данных становятся доступными пользователям субд благодаря ее языковым средствам
| Вид материала | Лекция |
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
- Курс, 1 поток, 5-й семестр лекции (34 часа), экзамен, 52.85kb.
- Программа дисциплины «Базы данных», 395.38kb.
- Программа дисциплины «Базы данных», 380.05kb.
- Рабочая программа По дисциплине «Базы данных» По специальности 230102. 65 Автоматизированные, 204.1kb.
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Сервер базы данных, 57.6kb.
- Лекция 2 Базы данных, 241.25kb.
- Новые возможности субд линтер алексей Егоров, Михаил Ермаков релэкс тезисы доклада, 13.42kb.
- Программа курса лекций "Базы данных в научных исследованиях", 49.32kb.
Базы данных, базы знаний и экспертные системы 2 Лекция 8
Языковые средства СУБД.
Общая характеристика языков баз данных.
Функциональные возможности моделей данных становятся доступными пользователям СУБД благодаря ее языковым средствам. В данном случае речь идет о пользователях СУБД, к числу которых можно отнести: персонал администрирования данными, разработчиков прикладных программ на основе СУБД и конечных пользователей системы. Пользователи каждой их этих категорий могут иметь специально предназначенные для них интерфейсы на том или ином уровне архитектуры системы.
Реализация языковых средств интерфейсов может быть осуществлена различными способами:
- для высококвалифицированных пользователей языковые средства представляются в их явной синтаксической форме;
- в других случаях функции языков могут быть доступны косвенным образом, когда они реализуются в форме различного рода меню, диалоговых сценариев или заполняемых пользователем таблиц. По таким входным данным интерфейсные средства формируют адекватные синтаксические конструкции языка интерфейса и передают их на исполнение или включают в генерируемый код языка приложения. Интерфейсы с неявным использованием языка широко используются в СУБД для персональных ЭВМ. В этом случае используется (для реляционных СУБД), например, табличный язык Query-By-Example (QBE) , разработанный М.Злуфом.
Языковые средства используются для выполнения следующих функций:
- для описания представления базы данных на управляемых уровнях архитектуры системы;
- для инициирования выполнения операций манипулирования данными;
- для управления данными.
Первая из этих функций обеспечивается языком описания данных (ЯОД)- Shema Definition Language. Его часто называют языком определения данных. Описание данных средствами ЯОД называют схемой базы данных. Оно включает описание логической структуры данных и налагаемых на нее ограничений целостности в рамках тех правил, которые регламентированы моделью данных используемой СУБД. Помимо указанных функций, ЯОД некоторых СУБД обеспечивает возможности задания ограничения доступа к данным или полномочий пользователей.
Кроме того, многие системы не имеют своих самостоятельных языков для спецификации многоуровневых отображений данных. В таких случаях определение способов отображения также описывается средствами ЯОД одного из смежных архитектурных уровней. Они при этом включаются в схему базы данных.
Стоит заметить, что при проектировании архитектуры системы часто не уделяют внимания обеспечению естественного разделения функций архитектурных уровней. В результате в значительной мере утрачивается возможность достижения той степени независимости данных, которая потенциально способна обеспечить "чисто" реализованная многоуровневая архитектура. Наиболее часто встречающиеся дефекты архитектуры заключаются в том, что спецификации некоторых характеристик организации хранимых данных, законное место которых в схеме внутреннего представления, попадают в схему концептуального уровня.
ЯОД не всегда синтаксически оформляется в виде самостоятельного языка. Он может быть составной частью языка данных, сочетающего возможности определения данных и манипулирования ими.
Язык манипулирования данными (ЯМД)- Shema Manipulation Language позволяет запрашивать предусмотренные в системе операции над данными из базы данных, т.е. содержит набор операторов манипулирования данными, позволяющий заносить данные, удалять, модифицировать или выбирать их. Аналогично ЯОД ЯМД не обязательно выступает в качестве синтаксически самостоятельного языка СУБД.
В настоящее время имеются многочисленные примеры языков СУБД, объединяющих возможности описания данных и манипулирования данными и единых синтаксических рамках. Более того, в современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с базой данных, начиная от ее создания и обеспечивающий базовый пользовательский интерфейс с базами данных. Наиболее популярным и стандартным для реляционных СУБД является язык SQL (Structured Query Language), разработанный фирмой IBM и реализованный в реляционной СУБД System R , а впоследствии и в коммерческой системе DB2. Другим примером языков этого класса могут служить: язык Quel системы Ingres , созданный Калифорнийским университетом, языковые средства большинства СУБД для персональных ЭВМ, например, язык dBase семейства СУБД фирмы Asthon - Tate и многочисленных совместимых с ним систем, язык СУБД: R:Base фирмы Microrim.
Некоторые СУБД располагают такими языками, которые не только реализуют функции определения и манипулирования данными, но и обладают управляющими структурами и другими средствами, свойственными традиционным языкам программирования. Благодаря этому они могут использоваться как функционально полное средство для создания прикладных программ и для формулировки запросов пользователей к БД. Такие языки называют автономными (язык запросов). В качестве примера приведем ранее упоминавшийся язык dBase , построенный в стиле структурного программирования.
Хотя автономные языки современных СУБД и обладают развитыми функциональными возможностями, существует много приложений, для реализации которых этих возможностей оказывается недостаточно. Наиболее распространены случаи, когда поддерживаемая модель данных оказывается слишком бедна средствами моделирования семантики предметной области.
Как уже отмечалось, конечные пользователи информационной системы разделяются на две категории - прямые и косвенные. Те, кто относится к группе прямых пользователей, в отличие от косвенных, самостоятельно без посредников общается с ЭВМ. Они способны разрабатывать новые приложения.
В настоящее время акцент разработки приложений все более переносится с профессиональных программистов на конечных пользователей. Эта тенденция имеет очевидные достоинства: приложения разрабатываются быстрее; реализуются именно те алгоритмы, которые необходимы пользователю в момент разработки приложений; снижается себестоимость программной реализации системы и упрощается весь процесс ее разработки. Все это становится возможным, если в состав СУБД входят языки конечных пользователей, которые относят к классу автономных непроцедурных языков высокого уровня. Сегодня почти для всех промышленных систем такие языковые средства разработаны.
Языки конечных пользователей позволяют осуществлять выборку данных, формировать отчеты, разрабатывать новые приложения и запрашивать выполнение уже разработанных. В некоторых языках такого типа обеспечены также возможности обновления базы данных и реализация достаточно сложных обработок данных.
Изучение простейших возможностей языков конечных пользователей не требует больших затрат времени. Такой уровень подготовки (обычно 1-3 дня) позволит пользователю разрабатывать несложные приложения.
Использование всего арсенала языков, необходимого для создания сложных процедур обработки данных, требует профессиональной подготовки.
Процедурный язык, при помощи которого осуществляется управление базой данных, называют языком управления данными.
Язык QBE (Query-By-Example).
Это язык, относящийся к классу высокоуровневых языков управления базами данных и представляющий пользователю удобный и унифицированный интерфейс для осуществления операций по ведению базы данных.
Для пользователя решение основных задач производится через таблицу-шаблон, связанную с реальной базой данных.
В QBE фундаментальными являются две концепции: 1) программирование осуществляется посредством двумерных таблиц-шаблонов; это достигается заполнением соответствующих полей таблицы в примере решения; 2) проводится различие между постоянным элементом и элементом примера.
Важно, что для выполнения действий над базой пользователю достаточно обладать элементарным запасом языков средств, чтобы понимать и использовать возможности всего языка. Синтаксис языка прост, тем не менее охватывает широкий спектр сложных операций. Это достигается за счет использования одинаковых операций для извлечения, манипулирования, определения и контроля данных. Операции языка “подражают” ручному манипулированию таблицами, сохраняя при этом все требования реляционной модели. Формирование операций должно следовать процессу рассуждений пользователя, предоставляя тем самым свободу при их построении. Архитектура языка QBE направлена на удовлетворение сформулированных требований. Более подробно анализ языка QBE может быть предложен в статье М.М.Злуфа Query-By-Example: язык баз данных (журнал «СУБД» №3,1996).
Язык SQL - фактический стандарт для реляционных СУБД.
Сами по себе данные в компьютерной форме не представляют интерес для пользователя, если отсутствуют средства доступа к ним. Доступ осуществляется в виде запросов, которые формулируются на стандартном языке запросов. Сегодня для большинства СУБД таким языком является SQL.
Его появление и развитие как средства описания доступа к базе данных связано с созданием теории реляционных баз данных. Прообраз языка возник в 1970 году в лаборатории Санта-Тереза фирмы IBM в рамках научно-исследовательского проекта System/R. Первоначально он назывался SEQUEL(Structured English Query Language), потом SEQUEL/2, а затем просто – SQL. Сегодня - это фактический стандарт интерфейса с современными СУБД. Популярность его настолько велика, что разработчики нереляционных СУБД (например, ADABAS), снабжают свои системы SQL-интерфейсом.
Язык SQL имеет официальный стандарт - ANSI/ISO. Большинство разработчиков придерживаются этого стандарта, однако часто расширяют его для реализации новых возможностей обработки данных.
В настоящее время существует три уровня языка: начальный, промежуточный и полный. Многие производители своих СУБД применяют собственные реализации SQL, основанные как минимум на начальном уровне соответствующего стандарта ANSI, и содержащие некоторые расширения, специфические для той или иной СУБД.
SQL не является языком программирования в традиционном представлении. На нем пишутся не программы, а запросы к базе данных, поэтому это язык называют декларативным, не процедурным. Это означает, что с его помощью можно сформулировать, что необходимо получить, однако нельзя указать, как это следует сделать. В частности, в отличие от процедурных языков программирования (Си, Паскаль), в языке SQL отсутствуют алгоритмические конструкции, операторы цикла, условные переходы и т.д.
Запрос в языке SQL состоит из одного или нескольких операторов, следующих один за другим и разделенных точкой с запятой. Наиболее важные операторы выделены в стандарте ANSI/ISO SQL.
Для пользователя представляют интерес не сами операторы языка, а их последовательность, оформленная как единое целое и имеющая смысл с этой точки зрения. Каждая такая последовательность операторов языка SQL реализует определенное действие над базой данных. Оно осуществляется за несколько шагов, на каждом из которых над таблицами выполняются определенные действия.
Повторяем, что SQL- это язык запросов, поэтому на нем невозможно написать достаточно сложные прикладные программы, которые работают с базой данных. Для этой цели в современных СУБД используют язык четвертого поколения (Forth Generation Language), обладающий как основными возможностями процедурных языков третьего поколения (Си, Паскаль), так и возможностью встроить в текст программы операторы SQL, так и средствами управления интерфейсом пользователя (формами, меню, вводом пользователя и т.д.). Сегодня - 4GL - это один из фактических стандартов разработки приложений, работающих с базами данных.
Первый стандарт языка появился в 1989 г. - SQL-89 - и поддерживался практически всеми коммерческими реляционными СУБД. Он имел весьма общий характер и допускал широкое толкование. Достоинствами SQL-89 можно считать стандартизацию синтаксиса и семантики операторов выборки и манипулирования данными, а также фиксацию средств ограничения целостности базы данных. Однако в нем отсутствовали такие важные разделы как манипулирование схемой базы данных и динамический SQL.
Неполнота стандарта SQL-89 привела к появлению в 1992г. следующей версии языка SQL. SQL-92 охватывает практически все необходимые проблемы: манипулирование схемой базы данных, управление транзакциями и сессиями, динамический SQL. В стандарте существуют три уровня: базовый, промежуточный и полный. Только в последнее время СУБД ведущих производителей обеспечивается совместимость с полным вариантом языка.
Появление новых требований пользователей к СУБД и обрабатываемым данным привели к тому, что в настоящее время ведется работа по разработке SQL 3. Эта версия языка, видимо, будет иметь в своем составе механизм триггеров, определение произвольного типа данных, серьезные объектные расширения. Пока же крупнейшие производители СУБД затягивают разработку этого стандарта, совершенствуя и расширяя собственные версии языка SQL. Более подробную информацию о возможностях языка SQL можно найти в статье «SEQUEL 2: унифицированный подход к определению, манипулированию и контролю данных» Д.Д.Чембелена, М.М.Астрахан и др. (журнал «СУБД» №1, 1996).
Процесс обработки SQL- запроса представлен схематично на рис.1
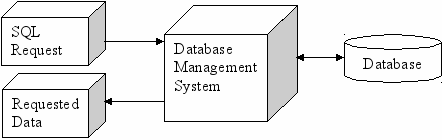
Рис.1 Обработка SQL – запроса базой данных.
Основные операторы языка SQL.
Data Definition Language (DDL).
Эта составляющая языка содержит операторы, позволяющие создавать, модифицировать и уничтожать базы данных и объекты внутри них (таблицы, представления) (см. таблицу 1).
Операторы DDL. Таблица 1.
-
Оператор
Описание
CREATE TABLE
Добавление новой таблицы к базе данных
DROP TABLE
Удаление таблицы из базы данных
ALTER TABLE
Изменение структуры имеющейся таблицы
CREATE VIEW
Добавление нового представления к базе данных
DROP VIEW
Удаление представления
CREATE INDEX
Создание нового индекса
DROP INDEX
Удаление существующего индекса
Data Manipulation Language (DML).
Эта составляющая языка содержит операторы, позволяющие добавлять, выбирать, удалять и модифицировать данные. Эти операторы не обязательно должны завершать транзакцию, внутри которой они вызваны. Описание операторов представлено в таблице 2.
Операторы DML. Таблица 2.
-
Оператор
Описание
SELECT
Выбор данных
INSERT
Вставка данных
DELETE
Удаление данных
UPDATE
Обновление данных
Иногда оператор SELECT относят к отдельной категории Data Query Language (DQL).
Transaction Control Language (TCL).
Операторы данного класса (см. таблицу 3) применяются для управления изменениями, выполняемыми группой операторов DML.
Операторы TCL. Таблица 3 .
| Оператор | Описание |
| COMMIT | Завершение транзакции и сохранение изменений в базе данных |
| ROLLBACK | Откат транзакции и отмена изменений в базе данных |
| SET TRANSACTION | Установка параметров доступа к данным в текущей транзакции |
Data Control Language (DCL).
Операторы Data Control Language (см. таблицу 4), иногда называемые операторами Access Control Language, применяются для осуществления административных функций, присваивающих или отменяющих право (привилегию) использовать базу данных, таблицу базы данных, а также выполнять те или иные операторы SQL.
Операторы DCL. Таблица 4.
-
Оператор
Описание
GRANT
Присвоение привилегии
REVOKE
Отмена привилегии
Все операторы SQL имеют вид, представленный на рис.2.
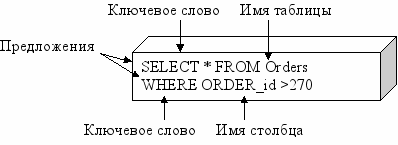
Рис.2 Структура оператора SQL
Каждый оператор SQL начинается с ключевого слова, которое определяет, что делает этот оператор (SELECT, INSERT, DELETE). В операторе содержатся предложения, содержащие сведения о том, над какими данными производятся операции. Каждое предложение начинается с ключевого слова, такого как FROM, WHERE и др. Структура предложения зависит от его типа: ряд предложений содержит имена полей или таблиц, некоторые могут включать дополнительные ключевые слова, константы или выражения.
Работа с операторами SQL.
Выбор данных.
Выбор данных представляет собой наиболее часто встречающуюся операцию, выполняемую с помощью языка SQL. Оператор SELECT - один из наиболее важных операторов, применяемый для выполнения процедур выборки. Синтаксис этого оператора представлен ниже:
SELECT столбцы (или *)
FROM отношение (я)
[WHERE ограничение(я)]
[ORDER BY столбец];
Операторы SELECT должны содержать слова SELECT и FROM. Другие ключевые слова, такие как WHERE или ORDER, являются необязательными.
За ключевым словом SELECT следуют сведения о том, какие именно поля необходимо включить в результирующий набор данных. Звездочка (*) означает, что в набор данных попадают все поля таблицы. Если выбор данных осуществляется из нескольких таблиц одновременно, и при этом выбираются одноименные поля, необходимо указывать на имена таблиц для полной идентификации полей, включаемых в результирующий набор данных.
SELECT Поставщики.наименование_компании, Клиенты.наименование компании
Предложение FROM
Для указания имен таблиц, из которых выбираются записи, применяется ключевое слово FROM, например:
SELECT *
FROM Поставщики.
Этот запрос возвратит все поля из таблицы Поставщики.
Предложение WHERE
Для фильтрации результатов, возвращаемых оператором SELECT, можно использовать предложение WHERE, синтаксис которого имеет вид:
WHERE выражение1 [{AND OR} выражение 2 […] ].
В предложении WHERE можно использовать различные выражения, например:
SELECT *
FROM Поставщики
WHERE Адрес_город= «Москва» AND Дата_договора =1998
или
SELECT наименование, цена
FROM Товар
WHERE скидка IS NOT NULL
Выражение IS NOT NULL означает, что соответствующая колонка результирующего набора данных не должна иметь пустых значений. В предложении WHERE могут использоваться как простые, так и специальные операторы сравнения (см. таблицу 5).
Операторы сравнения. Таблица 5.
-
Оператор
Описание
>,<,=, <=,>=,<>
Больше, меньше, меньше или равно, больше или равно, не равно
ALL
Применяется совместно с операторами сравнения при сравнении со списком значений
BETWEEN
Применяется при поверке нахождения значения внутри заданного интервала (включая границы)
IN
Применяется для проверки значения в списке
LIKE
Применяется при проверке соответствия значений заданной маске
Приведем примеры применения вышеуказанных операторов:
SELECT наименование, цена
FROM Товар
WHERE наименование BETWEEN ‘К ‘AND ‘Н’
Выбирает наименование товара, начинающегося с букв от К до Н.
SELECT наименование, цена
FROM Товар
WHERE наименование_производителя LIKE ‘%гидро%’
Выбирает наименование товара, в названии производителя которого содержится подстрока «гидро».
Предложение ORDER BY
Это предложение является необязательным и применяется для сортировки результирующего набора данных по одной ил нескольким колонкам. Для определения направления сортировки используются ключевые слова ASC (по возрастанию) или DESC (по убыванию). По умолчанию сортировки производится по возрастанию.
Синтаксис предложения имеет вид:
ORDER BY столбец 1 [{ASC DESC}] [,столбец2 [{ASC DESC}] [,..]
SELECT наименование, цена
FROM Товар
WHERE наименование BETWEEN ‘К ‘AND ‘Н’
ORDER BY цена
Связывание таблиц
При помощи операторов языка SQL можно извлекать данные более чем из одной таблицы. Одна из возможностей сделать это заключается в связывании таблиц по одному общему полю. Однако даже без связывания таблиц в результате оператора получится набор данных, содержащий все возможные комбинации строк каждой из исходных таблиц (декартово произведение):
SELECT наименование_продукта, категория_продукта
FROM Продукт, Категория
Запрос, показанный ниже, указывает, какой категории принадлежит данный продукт:
SELECT наименование_продукта, категория_продукта
FROM Продукт, Категория
WHERE Продукт.категория_номер=Категория.категория_номер
Присутствующее в операторе ограничение указывает, что из связываемых таблиц извлекаются только те строки, в которых атрибуты «номер» имеют одинаковое значение Название столбца указывается только вместе с названием таблицы; в противном случае оператор будет неоднозначным.
Можно использовать другие типы связывания таблиц: оператор INNER JOIN (внутреннее соединение) обеспечивает присутствие в результирующем наборе записей, значения в связанных полях которых совпадают. Внешние соединения (OUTER JOIN) позволяют включить в результат запроса все строки из одной таблицы и соответствующие им строки из другой, например:
SELECT наименование_продукта, категория_продукта
FROM Продукт LEFT OUTER JOIN Категория
WHERE Продукт.категория_номер=Категория.категория_номер
Предложения GROUP BY
Для вычисления суммарных значений на основе данных одной или нескольких таблиц можно использовать предложение GROUP BY, имеющее следующий синтаксис:
GROUP BY {столбец1} [,..]
В этом случае результаты, возвращенные функцией, будут сгруппированы по одинаковым значениям атрибута группировки. Можно использовать как агрегатные функции, так и строковые математические функции для проведения операций группировки данных. Так, сумму баллов, полученных абитуриентом на экзамене можно получить с помощью следующего запроса:
SELECT DISTINCTROW Оценки. номер абитуриента, Sum(Оценки. полученный балл) AS Sum_Полученный балл
FROM Оценки
GROUP BY Оценки. номер абитуриента;
Предложение GROUP BY сообщает системе, что надо разбить заданное отношение на группы кортежей с одинаковыми значениями атрибута «номер абитуриента». В результате для каждой группы будет возвращена строка, представляющая суммарный балл с определенным значением номера абитуриента. В первой строке необходимо указывать атрибут, по которому будет производиться группировка. При использовании функций не разрешается (!) в верхней строке оператора (в предложении SELECT) указывать имена атрибутов, не входящих в предложение GROUP BY. В одном операторе можно указывать несколько функций.
На создаваемые подгруппы можно накладывать ограничения с помощью предложения HAVING. в следующем примере оператор возвратит только строки, у которых суммарный балл больше 12.
SELECT DISTINCTROW Оценки. номер абитуриента, Sum(Оценки. полученный балл) AS Sum_Полученный балл
FROM Оценки
GROUP BY Оценки.номер абитуриента;
HAVING Sum(Оценки.полученный балл)>12
Ключевые слова ALL и DISTINCT
Эти ключевые слова управляют выводом дублирующих строк результирующего набора записей. Ключевое слово DISTINCT указывает, что строки результирующего набора должы быть уникальны, в то время как ключевое слово ALL указывает, что возвращать необходимо все строки.
Вложенные последовательности запросов.
В SQL можно создавать вложенные последовательности запросов. Например, в результате выполнения следующего запроса будут перечислены все номера клиентов, имеющих счета в филиале «Бауманский»:
SELECT номер_клиента
FROM Счета_клиентов
WHERE номер_счета IN
(SELECT номер_счета
FROM Счета
WHERE филиал= «Бауманский»)
В данном случае подзапрос возвращает множество кортежей, состоящих из номеров_счетов отношения Счета, которые обрабатывает филиал «Бауманский». Он вложен во внешний запрос, который сравнивает номера-счетов каждого кортежа отношения Счета_клиентов с возвращенным внутренним запросом множеством номеров счетов. Если рассматриваемый номер счета есть в указанном множестве, будет возвращен номер_клиента этого кортежа. Для проверки принадлежности к множеству используется оператор IN.
Существуют определенные типы запросов, которые лучше реализовывать с помощью подзапросов; преимущественно это так называемые проверки существования. Предположим, что требуется получить данные о клиентах, которые не имеют счетов. Можно создать следующий запрос с вложенным подзапросом:
SELECT *
FROM Клиенты
WHERE номер_клиента NOT IN
(SELECT номер_клиента
FROM Клиенты_счета)
Если будет возвращено пустое множество, то это означает лишь одно – у каждого клиента есть, по крайней мере, один счет.
Модификация данных.
Оператор UPDATE
Для изменения значений в одном или нескольких столбцах таблицы испльзуется оператор UPDATE. Синтаксис этого оператора имеет вид:
UPDATE таблица
SET столбец1= выражение1 [, столцец2= выражение2] […]
[WHERE условие]
Выражение в предложении SET может быть константой или результатом вычислений.
UPDATE Счет
SET баланс=баланс+1000.00
WHERE баланс>0
Оператор DELETE
Оператор используется для удаления строк из таблиц, синтаксис оператора имеет вид:
DELETE
FROM таблица
[WHERE условие]
Предложение WHERE не является обязательным, однако, если его не включить, то будут удалены все записи таблицы. Полезно использовать оператор SELECT c тем же синтаксисом, что и оператор DELETE, чтобы предварительно проверить, какие записи будут удалены.
Оператор INSERT
Оператор выполняет функцию добавления записей в таблицу и имеет следующий синтаксис:
INSERT INTO
([список столбцов]
{VALUES ({DEFAULT|NULL|выражение}
} [,..]
)
Определение данных в SQL.
Создание таблиц –CREATE TABLE
Чтобы из таблицы извлекать данные, необходимо ее существование в базе данных; базовое отношение создается с помощью оператора CREATE TABLE. Синтаксис этого оператора имеет вид:
CREATE TABLE таблица
(столбец1 тип1 [(размер1)]
[,...]
)
В этом операторе следует указать имя поля, тип данных для него, длину (для некоторых типов данных). Например, создадим таблицу Заказ с полями: номер_заказа, ФИО_исполнителя, сумма_заказа, где номер_заказа – первичный ключ:
CREATE TABLE Заказ
(номер_заказа Integer(6) NOT NULL PRYMARY KEY,
ФИО_исполнителя CHAR (20),
Сумма_заказа Integer(4)
)
Нельзя использовать оператор создания таблицы несколько раз для одной и той же таблицы. Если после ее создания обнаружились неточности в ее определении, то внести изменения можно с помощью оператора ALTER.
Оператор ALTER TABLE
Этот оператор предназначен для изменения структуры существующей таблицы; применяя его можно удалить или добавит поле к существующей таблице:
1.добавление поля
ALTER TABLE таблица ADD [COLUMN] столбец тип столбца
[(размер)]
2.удаление поля
ALTER TABLE таблица DROP [COLUMN] столбец
[(размер)]
Дополнительные ограничения
Для того чтобы указать, что данное поле должно иметь определенное значение в каждой строке таблицы, необходимо указывать ограничение NOT NULL. Это ограничение можно накладывать на любой столбец таблицы, если необходимо запретить задание неопределенных значений.
Для указания того факта, что атрибут является первичным ключом, указывается ограничение PRIMARY KEY; данное ограничение не прикрепляется к отдельному столбцу, а относится ко всей таблице в целом. Первичный ключ может распространяться более чем на один атрибут таблицы, тогда ограничения налагаются следующим образом:
CREATE TABLE Заказ
(номер_товара NOT NULL ,
цена NOT NULL,
PRYMARY KEY (номер_товара, цена)
Существует ограничение на уникальность атрибутов, не являющихся первичным ключом отношения – UNIQUE. Это ограничение можно использовать, если есть необходимость определить потенциальные ключи отношения.
Для реляционной модели данных существенным является указания внешнего ключа. При объявлении внешних ключей необходимо наложить соответствующие ограничения на столбец. Например, в таблице Счета клиентов существует два внешних ключа «номер_счета» и «номер_клиента». Они задаются следующим образом:
CREATE TABLE Счета_клиентов
(номер_счета NOT NULL REFERENCES Счет,
номер_клиента NOT NULL RFERENCES Клиент,
PRYMARY KEY (номер_счета, номер_клиента)
На отдельные атрибуты могут накладываться семантические ограничения, обеспечивающие целостность данных. В таких случаях можно использовать предложение CHECK, чтобы ограничить множество допустимых значения определенного столбца:
CREATE TABLE Товар
(номер_товара INTEGER (5) NOT NULL PRIMARY KEY,
категория_товара CHAR (1)
CHECK (категория_товара = ‘A’ OR категория_товара=’D’
);
При таком задании ограничения атрибута «категория_товара» любая попытка ввести значения, отличные от ‘А’ и ‘D’ будет отклонена.
Создание представлений
Представление – логическое отношение, содержимое которого является производным уже существующим отношениям. В языке SQL представление создается при помощи оператора SELECT, который позволяет задать содержимое представления:
CREATE VIEW Счет1
AS
SELECT * FROM Cчет
WHERE тип_счета = ‘депозитный’
Удаление объектов базы данных
Таблицы, представления удаляются из базы данных при помощи оператора DROP.
DROP TABLE Клиент;
DROP VIEW Счета_клиентов.
При удалении таблицы удаляются все представления, которые ссылаются на нее.
Управление доступом к данным в SQL.
Доступ к данным в многопользовательской среде регулируется с помощью операторов GRANT и REVOKE. В каждом операторе необходимо уазать пользователя, объект (таблицу, представление), по отношению к которому задаются полномочия, и сами полномочия. Следующий оператор GRANT задает пользователю Х возможность производить выборку данных из таблицы Клиент:
GRANT SELECT ON Клиент TO X
Оператор REVOKE аннулирует все предоставленные ранее полномочия.
В заключении хочется еще раз упомянуть о перспективах развития языка SQL. Создаваемая версия SQL:2003 включает три составные части, которых не существовало в предыдущей версии: дополнение для программ и типов Java под названием «Картриджы методы Java», средства для оперативной аналитической обработки и связки SQL-XML; данная версия является объектно-ориентированной. Многие участники Комитета по стандарту SQL считают, что современный язык, несомненно, более разнообразен по выполняемым функциям, и в первую очередь потому, что в него включены возможности для моделирования более сложного, реального мира. Существуют попытки переориентации разработчиков СУБД на использование иных языковых средств, однако, можно сформулировать три причины все-таки применения SQL: математическая платформа. Он описывает мир лучше предыдущих технологий и поэтому он более привлекателен бизнесу с точки управления данными, и, наконец, этот язык удачно соответствует сложившейся образовательной структуре, что обеспечивает формирование кадровых ресурсов.
Ключевые слова:
языковые средства
непроцедурный язык
язык запросов
язык описания данных (DDL)
язык манипулирования данными (DML)
язык управления данными
автономные языки
язык конечных пользователей
декларативный язык
SQL
QBE
Рекомендуемая литература:
- Горев А., Ахаян Р., Макашарипов С. Эффективная работа с СУБД. - СПб.: Питер, 1997. – 704 с.
- Дейт К. Дж. Введение в системы баз данных.: Пер. с англ. - 6-е изд. - К.: Диалектика,1999. – 784 с.
- Кагаловский М.Р. Энциклопедия технологий баз данных. – М.: Финансы и статистика, 2002. – 800с.
- Ф.Д.Ролланд Основные концепции баз данных: Пер.с англ.- М.: Издательский дом «Вильямс», 2002 – 256с.
- С.Кузнецов SQL: язык реляционных баз данных. – М. Майор, 2001. – 191с.


Н.Алтухова, 2004 www.inf-man.ru