
Вопрос №1. "Понятие системы. Примеры системы. Свойства сложных систем"
| Вид материала | Документы |
| Время реакции на запрос. Уровень 1 - внешний Уровень 3 - концептуальный |
- Производственное планирование в структуре логистического менеджмента промышленного, 179.15kb.
- Вопросы к экзамену по дисциплине «поверхностные явления и дисперсные системы», 37.35kb.
- Исследование сложных систем основано на системном подходе, 143.97kb.
- Календарно тематический план занятий Предмет: информационные системы в экономике для, 38.5kb.
- Программа по специальным дисциплинам: по дисциплине «Деньги, кредит, банки»: Тема., 288.06kb.
- Программа по специальным дисциплинам: по дисциплине «Деньги, кредит, банки»: Тема., 289.08kb.
- Вопросы к государственному экзамену по специальности «Прикладная математика» (специализация, 70.84kb.
- О. Ю. Якубовская 2011 г. Дисциплина: Операционные системы (2 часть из 2) Специальность:, 45.21kb.
- 1. понятие компьютерного моделирования, 110.25kb.
- О создании Методов Многомерной Визуализации, 171.04kb.
Время реакции на запрос.
 Т. ожид. Т 0
Т. ожид. Т 0



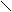 t = Tn/2 Работа процессора Работа Т. ожид На
t = Tn/2 Работа процессора Работа Т. ожид На


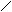

 интерпретации ядра экран
интерпретации ядра экранТ.
Т общ. = ожид.


Работа
накопителя
Вопрос №23. Функции администратора БД.
Администратор базы данных (АБД) - под этим понятием подразумевается лицо (или группа лиц, возможно, целое штатное подразделение), на которое возложено управление средствами базы данных организации.
АБД должен быть энергичной и способной личностью, организатором по призванию, желательно с техническим уклоном.
В его функции входит:
- координировать все действия по проектированию, реализации и ведению БД; учитывать перспективные и текущие требования пользователей; следить, чтобы БД удовлетворяла актуальным информационным потребностям;
- решать вопросы, связанные с расширением БД в связи с изменением границ ПО;
- разрабатывать и реализовывать меры по обеспечению защиты данных от некомпетентного их использования, от сбоев технических средств, по обеспечению секретности определенной части данных и разграничению доступа к данным;
- выполнять работы по ведению словаря данных; контролировать избыточность и противоречивость данных, их достоверность;
- следить за тем, чтобы БнД отвечал заданным требованиям по производительности, т. е. чтобы обработка запросов выполнялась за приемлемое время; -выполнять при необходимости изменения методов хранения данных, путей доступа к ним, связей между данными, форматов данных; определять степень влияния изменений в данных на всю БД; -координировать вопросы технического обеспечения системы аппаратными средствами исходя из требований, предъявляемых БД к оборудованию;
- координировать работы системных программистов, разрабатывающих дополнительное программное обеспечение для улучшения эксплуатационных характеристик системы.
- координировать работы прикладных программистов, разрабатывающих новые ПП и выполнять проверку и включение прикладных программ в состав программного обеспечения системы И Т. П.
Вопрос №24. "СУБД. Определение и архитектура".
СУБД - комплекс программных средств, который позволяет создать БД (файл, структура и хранение в котором построены так, что информация из него берется путем запроса), поддерживать ее в актуальном состоянии и осуществляет выдачу ответов на запросы БД.
Основные функции СУБД:
- создание БД;
- поддержка логической (изменение логических представлений, не затрагивая их физических представлений) и физической независимости данных;
- организация доступа пользователю;
- разграничение прав доступа пользователю: явное указание прав доступа, паролевая защита;
- обеспечение логической (наличие непротиворечивых данных) и физической (сохранность на физическом уровне: копирование, организация зеркальных дисков) целостности данных;
- должны быть средства настройки;
- организация многопользовательской работы.
Модули СУБД:
- ядро, которое управляет накопителем;
- окружение системы - ряд утилит, которые выполняют определенные действия:
- утилиты администрирования,
- средства разработки приложений,
- утилиты копирования, восстановления,
- утилиты импорта / экспорта файла,
- обучающая утилита.
Архитектура СУБД:
Архитектура - компоненты, которые поддерживают определенный взгляд на данные.
Уровень 1 - внешний: компоненты, которые поддерживают уровень пользователя.
Уровень 2 - внутренний: функциональные компоненты, которые поддерживают БД в среде хранения.
Уровень 3 - концептуальный: обеспечивает единый взгляд на БД. Этот уровень содержит внешний интерфейс (связь с пользователем) и внутренний интерфейс (связь между уровнями).
Вопрос №25. Понятие и назначение интерфейса при проектировании БД
Наиболее развитые СУБД имеют следующие преимущества и характерные особенности:
- "дружественный" интерфейс с пользователем;
- встроенную программу интерактивной помощи, а иногда и наличие интерактивной обучающей программы;
- средства автоматического создания, использования и модификации базы данных без необходимости программирования, генераторы программ, отчетов, форматов;
- развитые языки программирования баз данных — более 200 команд и функций.
Дружественная система такого рода предлагает пользователю иерархически построенное меню. С его помощью выбирается требуемая функция системы.
Для ввода данных, их просмотра и редактирования в базе данных чаще всего используются два способа их представления - табличный и в виде экранных форм. Экранные формы применяют в случаях, когда длина записи данных превышает размер строки дисплея или когда удобнее работать с привычной формой документа. Для изображения форм ввода-вывода применяется обычно псевдографика, и выводятся они на экран в текстовом режиме. Вывод результатов обработки пользовательских запросов осуществляется в виде так называемых отчетов. Наиболее часто используются отчеты табличной формы.
Записи в такой таблице обычно сортируются по заданному ключу. Для групп записей с одинаковым значением некоторой части ключа или полного ключа, а также для всего множества записей могут строиться итоговые значения по заданным столбцам таблицы. Допускается иерархия группирования записей, и для разных инструментальных средств возможна различная ее глубина.
Наряду с табличной используется и так называемая ленточная или свободная форма отчета, каждая запись которого может занимать несколько строк, и форматы разных записей могут быть различны.
Выводимые прикладной системой отчеты могут выводиться на экран дисплеем или печататься на принтере.
Традиционно построенное приложение использующее перечисленные функциональные компоненты, предусматривает выполнение некоторого набора типовых процедур. Обеспечивается, в частности, ввод записей в базу данных с верификацией их по заданным простым ограничениям целостности, например, по диапазону изменения значений числового поля формы или по шаблону значения строкового поля. Кроме того, возможны просмотр, редактирование и удаление записей, а также поиск записей по задаваемому через экранную форму критерию. При этом пользователь задает значения поисковых полей формы, имея в виду, что в результате поиска должны быть найдены и показаны все записи, имеющие такие же значения всех поисковых полей. К числу типовых процедур приложения относится также вывод отчета по любой форме, известной системе, на экран дисплея или на принтер.
Дружественный характер СУБД для ПЭВМ хорошо сочетается с главной направленностью технологии персональных ЭВМ на обеспечение комфортных условий работы пользователей. Благодаря этому достигается существенно более высокая производительность труда пользователя при создании и эксплуатации "персональных" баз данных, чем при выполнении подобных работ на "больших" ЭВМ со свойственными их социальной пользовательской среде значительными накладными расходами и более низкой надежностью.
Интерфейс СУБД с различными классами пользователей обычно обеспечивается широким диапазоном языков. В нем также предусматриваются соответствующие средства для проектирования и использования баз данных. В подавляющем большинстве СУБД для ПЭВМ предусматривается интерактивный режим работы пользователей. При этом широко используются интерфейсы в стиле меню с указанием для пользователя альтернативных вариантов выбора возможных действий и способов их инициирования, с отображением текущего состояния системы БД и диагностикой ошибок. В системах, обладающих языками программирования ("программируемые" СУБД), средства такого интерфейса избавляют пользователя от необходимости знания команд языка программирования для выполнения требуемых функций.
Благодаря этому расширяется круг возможных пользователей системы. В некоторых развитых СУБД предусматривается несколько уровней пользовательских интерфейсов, предъявляющих различные требования к их квалификации. Такие возможности предусмотрены, например, в системах dBaseIII РLUS и dВаsе IV, R:Base, Раrаdох. Значительное внимание уделяется минимизации с помощью функциональных клавиш действий пользователя, необходимых для инициирования часто требуемых функций. Освоение системных средств и интерпретация возникающих в процессе работы ситуаций существенно облегчаются благодаря созданию эффективных электронных учебников, средств глобальной и контекстно-зависимой помощи пользователю в оперативном режиме, а также средств диагностики ошибок. Такие средства стали необходимыми компонентами любого программного продукта для ПЭВМ.
Многие СУБД предоставляют пользователю возможность взаимного обмена данными, содержат соответствующие программы-конверторы для преобразования данных из одного формата в другой.
Сбалансированное сочетание простоты освоения и использования "поверхностных" функций таких массовых СУБД, как dBaseIII РLUS , R:Base, Раrаdох, обширных функциональных возможностей и прочих интерфейсов, обеспечивает этим системам широкую сферу применения. Например, первые впечатления от таких СУБД даже порождают у непрофессионального пользователя иллюзию того, что любую ИС можно реализовать вообще без какого-либо программирования в кратчайшие сроки и без заметных трудозатрат, что в этой области вообще не существует проблем и профессиональной специфики, требующей специальных знаний. Однако, по мере усложнения информационных потребностей, когда уже не удается обойтись средствами простейшего пользовательского интерфейса с системой и приходится прибегать к ее языку программирования, иллюзии начинают рассеиваться.
Если объемы данных в БД достигают значительных размеров, при выполнении операций, требующих прямого доступа, пользователя начинает беспокоить недостаточно высокая реактивность системы. Для решения проблемы повышения производительности системы БД уже недостаточно хорошего знания только языка программирования. Необходимы профессиональные знания в области технологии БД, понимание архитектуры системы, знание механизмов доступа к БД в рассматриваемой СУБД, умение эффективно проектировать базу данных.
Вопрос №26. Общая концепция и типы структур распределенных баз данных
Распределенная база - это база, распределенная на нескольких установках, но обеспечивается доступ к единственному информационному пространству. Для таких баз характерно наличие информационно - вычислительной сети. Архитектура распределенной базы должна соответствовать архитектуре сети (т.к. нет протоколов сети).
Структура распределенной базы бывает двух видов: однородная неоднородная.
Однородная база данных распределена на сегменты по функциональному признаку. Доступ осуществляется через единую сущность если таблицы не пересекаются. Обработка клиент - сервер затруднительна(т.к. на некоторых машинах нагрузка растет не пропорционально). Однородные базы применяются в основном для кольцевых сетей.
Неоднородные базы в свою очередь делятся на централизованные и децентрализованные.
В децентрализованных базах каждый пользователь может иметь свой сегмент который должен быть скопирован на центральный сервер. Вся обработка идет на машине пользователя. Процедура транзакции должна заканчиваться стиранием рабочей копии.
В централизованных базах работу конечного пользователя можно организовать на упрощенных терминалах. Вся обработка информации производится на центральном сервере клиенту выдается готовый ответ. Центральный сервер должен быть дубль машиной (работают одновременно две машины одна ведущая другая ведомая в случае разногласий должен вмешаться администратор ).
Вопрос №27. Жизненный цикл базы данных
Жизненный цикл - это развитие системы базы данных во времени.
Поэтому жизненный цикл базы данных можно разбить на следующие основные стадии:
- Проектирование;
- Эксплуатация;
- Вывод из эксплуатации.
Проектирование.
На стадии проектирования разрабатываются технический и рабочий проекты.
Техническое проектирование.
Во время технического проектирования базы данных проектировщик должен проделать следующую работу:
1. Обследовать предметную область автоматизации.
2. Определить объекты и перечень их атрибутов, для каждого объекта выделить первичные ключи и провести нормализацию.
3. Установить все структурные, иерархические связи между объектами и все запросные связи, обеспечивающие обработку всех запросов пользователей и баз данных. Начертить схему проекта со всеми объектами и связями.
4. Выработать технологию обслуживания базы данных
5. Выбрать компьютер и инструментальные средства (конкретную СУБД) для реализации.
6. Проверить корректность проекта.
7. Определить сроки реализации банка данных.
Рабочее проектирование.
На стадии рабочего проектирования базы данных необходимо проделать следующие работы:
1. Описать средствами СУБД и ввести в ЭВМ схемы всех отношений.
2. Разработать интерфейсы пользователей с базой данных.
3. Разработать программное обеспечение базы данных для всех приложений.
4. Заполнить базу данных контрольными данными и отладить ее.
5. Разработать контрольные примеры, провести тестирование системы и скорректировать технологию ее обслуживания.
6. Составить необходимые инструкции по системе и обучить пользователей.
Эксплуатация.
Ввод в эксплуатацию банков данных довольно длительный и сложный процесс, который предусматривает:
- Организацию сбора информации
- Заполнение БД
- Сдачу БД в эксплуатацию
- Реорганизация и реструктуризация при эксплуатации
Вывод из эксплуатации.
Существует правило, что сведенья из Базы Данных не должны уничтожаться, а передаются в Государственный архив. Срок хранения в архиве определяется ценностью информации. Так данные о заработной плате хранятся 75 лет. В архиве все хранится на магнитных лентах, поэтому вся База Данных переносится на твердый носитель. Выгрузка Базы Данных организовывается не по записям, а по полям. При этом может возникнуть сбой, если сдвинулся один из реквизитов. Поэтому при выгрузке Базы Данных происходит подсчет контрольных сумм в двоичном виде по строкам и по столбцам для нахождения сбоя в Базе Данных. Но при восстановлении утерянных символов существует опасность (10 процентов) получения неверного результата. Поэтому лучше заново загрузить блок. В этом случае надежность гарантируется.
Вопрос №28. Статические и динамические структуры данных, их особенности.
Ответ:
Существуют динамические и статические объекты. У обычные переменные сразу после её описания резервируется область памяти, и эта область закрепляется за переменной на все время работы программы. Такого рода переменные называют статическими переменными. Часто бывает так, что какая-то переменная нужна не на всё время выполнение программы, а только на какую-то часть этого времени. Такие временные программные объекты могут занимать значительный объем памяти и одновременное существование всех таких объектов может потребовать столь большого объема машинной памяти, что соответствующая программа просто не сможет разместиться в ограниченной оперативной памяти машины. Переменные которые могут резервировать область памяти, а затем снова освобождать во время выполнения программы стали называть динамическими. Динамические объекты будут возникать в процессе выполнения программы, а действия над ними необходимо задавать уже до выполнения.
В Паскале для работы с динамическими объектами предусматривается специальный тип переменных, так называемый ссылочный тип. Каждому динамическому объекту в программе сопоставляется статическая переменная ссылочного типа. В терминах этих ссылочных переменных обосновываются действия над соответствующими динамическими объектами.
Динамические объекты и ссылки:
<имя ссылочного типа> = <имя типа>,
где
- называемая «крышка», признак ссылочного типа,
<имя типа> - это имя либо статического, либо ранее описанного типа значения.
Рассмотрим листинг программы написанный на языке Паскаль:
Uses
Crt;
Type
masiv = array[1..10] of Integer;
DinMas = masiv;
RefMas = Real;
Var
p, d :Integer;
q
: char;
RabMas
:DinMas;
RefMas
: array [1..15] of RefReal;
r
:Integer;
Begin
End;
Значение переменной р может быть ссылкой на динамический объект целого типа. Значение переменной q - ссылка на динамический объект литерного типа. Значение переменной RabMas - ссылка на динамический объект значение, которого является массив из 10 целых чисел. Значения статических ссылочных переменных указывают место в памяти соответствующего динамического объекта. поэтому переменные ссылочного типа часто называют указателями.
Динамическому объекту в отличие от статических не дается имен в обычном понимание этого слова. Для ссылки на динамический объект в Паскале имеется такое понятие как переменная с указателем:
<имя переменной с указателем> = <ссылочная переменная> ,
где
<ссылочная переменная> - это имя той статической переменой ссылочного типа, которая в программе поставлена в соответствие данному динамическому типу.
«Крышка» после ссылочной переменной свидетельствует о том, что здесь речь идет не о значении ссылочной переменной, а о значении того программного объекта на которой указывает эта ссылочная переменная.
Отличия использования динамических переменных от статических переменных:
- вместо описания самих динамических переменных в программе даются описания указателей(статических переменных ссылочного типа) поставленных в соответствие динамическим переменным;
- в подходящем месте программы должно быть представлено порождение каждой из динамической переменной (в Паскале процедура New);
- для ссылки на динамическую переменную используется переменная с указателем.
Если в процессе выполнения программы некоторая динамический объект созданный ранее становиться не нужным, то его можно уничтожить, что позволит освободить оперативную память, которую он занимал.
Вопрос №29. Основные технологии программирования. Нисходящая и восходящая технологии программирования.
Ответ:
Методы регламентирующие высокий профессиональный уровень написания программ независимо или почти независимо от языка, операционной системы ЭВМ и решаемой задачи:
- система методов, способов и приемов разработки и отладки программ;
- совокупность организационно-административных и инженерно-технических средств поддерживающих создание, документирования, распространения и сопровождения программного продукта.
Для описания этих средств применяются графы, диаграммы и т.п. Унифицируется и стандартизируются административно-управленческие приемы и средства, коммуникатируются документация. Регламентируется этапность жизненного цикла программного продукта и применительно к этим этапам, разрабатывается нормативы производительного труда, надежность и качества изделий.
Основой технологии программирования служит модульность программы главной чертой которой является:
- стандартизация;
- паспортизация модулей;
- межмодульный интерфейс;
- унификация.
Технология программирования базируется на поэтапном построение программ, т. е. нисходящее и восходящее проектирование. Необходимость перехода к нисходящему проектированию при создании больших систем программного обеспечения стала очевидной в результате неудачных попыток по созданию программ из методов восходящего проектирования. Метод восходящего проектирования заключается в том, что вначале разрабатывается отдельные модули на языке низкого уровня, а затем они объединяются в систему. Поэтому недостатки проекта часто обнаруживаются только при отладке программного комплекса, т. е. оказывается, что множество модулей было написано и проверено только для того, чтобы быть затем забракованными. В противоположность этому при нисходящем проектировании сначала пишут и проверяются управляющие программы, а функциональные модули добавляют в процессе разработки системы. Таким образом, создание системы происходит путем её расширения уровень за уровнем с проверкой и объединением модулей в процессе программирования, а не после её окончания. На каждом уровне процесса проектирования отрабатываются программы обслуживания и определяются данные.
Нисходящее проектирование систем программного обеспечения обычно начинается с логического проектирования, обеспечивающего согласованную работу нескольких модулей, которым необходим доступ к совместно используемым данным.
Легко заметить, что преимущество нисходящего проектирования по сравнению с восходящим есть преимущество процесса при наличии обратной связи по сравнению с процессом без обратной связи. При восходящем проектировании программы не проверяются как составная часть системы до окончания разработки. При нисходящем же проектирование их проверяют сразу, в контуре системы. Если допущены ошибки в проектирование или в программирование, нисходящее проектирование позволяет обнаружить их на ранних этапах, когда программа еще находиться у разработчика. Восходящее же проектирование приводит к ошибкам, которые могут быть обнаружены только при комплексной отладки, когда разработчик модуля уже переключился на другую работу.
Разрабатывать программы с использованием метода нисходящего проектирования сложнее, чем применяя метод восходящего проектирования, но затраченные усилия окупаются на этапе объединения и отладки. Реализация метода нисходящего проектирования дает возможность предвидеть, что будет представлять собой система не только по окончанию разработки, но и на каждой промежуточной стадии. Продемонстрируем это на примере строительства моста. При проектирование моста на бумаге сначала изображают ферму, затем другие детали моста, в том числе опоры. Но для строительства моста нужен конструкторский план размещения каждой фермы и их соединений с помощью опор.
Разработка системы программного обеспечения методом восходящего проектирования напоминает проектирование моста на бумаге. Нужен только окончательный проект, и тогда можно надеяться, что и без конструкторского плана все пойдёт гладко. К сожалению, людям, в том числе и конструкторам, свойственно ошибаться, поэтому реализация этого подхода сопровождается рядом трудностей.
Нисходящее проектирование систем программного обеспечения схоже с реальным строительством моста. Нахождение главного звена проекта является важной и значительной технической проблемой. Главное звено - это то, которое разрабатывается как часть системы в первую очередь и является основой для разработки промежуточных и окончательных программ в непрерывном итерационном процессе, включающем кодирование, объединение модулей и тестированием.
Вопрос №30.Алгоритмические языки высокого уровня, их сравнительные характеристики.
Ответ:
Для сравнения выбраны два языка высокого уровня: Паскаль и Си.
Предпосылки.
Программы, написанные на языке Паскаль, отличаются большей надежностью, чем программы, написанные на языке Си. Основной причиной этого является сильная типизация в языке Паскаль, а кроме того, наличие в языке Паскаль более богатого набора типов данных. Это обеспечивает «удобочитаемость» и более высокую мобильность программ, написанных на Паскале, по сравнению с программами, написанными на Си. Однако в силу своей гибкости и отсутствия ограничений язык Си обеспечивает возможность использования его в более широком спектре областей применения.
Типы данных.
Наиболее существенное различие между Си и Паскалем - в трактовке типов данных в каждом из них. Если первый является результатом эволюционного развития безтиповых языков программирования, то второй был создан под влиянием языков программирования и развитой типизацией данных.
Язык программирования является языком программирования с сильной типизацией данных, если:
- каждый объект в этом языке программирования принадлежит точно одному из существующих в этом языке в этом языке программирования;
- преобразование типов осуществляется только путем преобразования значений из одного типа в другой;
- преобразование типов не производится путем трактовки представления значения как данных различных типов.
2. Сравнение особенностей языков СИ и ПАСКАЛЯ
2.1. Типы данных.
2.1.1. Описание переменных.
В языке Си описание переменных выглядит следующим образом:
[класс_памяти] [тип][список_переменных]
Область действия переменной зависит от связанного с этой переменной класса памяти и места в программе, где помещено описание этой переменной. Областью действия переменной может быть составной оператор или блок, функция, файл с исходным текстом, совокупность всех файлов с исходными текстами. Время жизни переменной определяется связанным с этой переменной классом памяти и может совпадать с временем выполнения составного оператора или блока, функции, программы.
Описание переменных в Си может сопровождаться их инициализацией определенным значением. Однако переменные, имеющие структурированные типы (например, массивы), могут быть инициализированы в процессе их описания только в том случае, если они являются статическими. По умолчанию статические переменные инициализируются значением 0. Следствием этого является отсутствие возможности обнаружения ошибок, связанных с неправильной инициализацией переменных.
В языке Паскаль описание переменных выглядит следующим образом:
var список_переменных: тип
Описание переменных в Паскале не может сопровождаться их инициализацией определенным значением. Поэтому инициализация переменных обязательно должна осуществляться до их использования с помощью оператора присваивания или ввода. Переменная является локальной по отношению к процедуре, внутри которой она описана, и глобальной по отношению к процедурам, вложенным в процедуру, внутри которой она описана. Время жизни переменной совпадает с временем выполнения процедуры, внутри которой она описана.
В Паскале массивы различного размера имеют различный тип. Это приводит к тому, что невозможно написать подпрограмму, аргументом которой является массив произвольного размера. По этой причине, например, невозможно создать библиотеку подпрограмм общего назначения для работы со строками.
В языке Си индексы массивов могут быть только целого типа и всегда начинаются с нуля. В Паскале в качестве индексов массивов могут быть использованы константы и переменные любого скалярного типа, кроме вещественного.
- Базовые типы данных.
В языке Си можно выделить три типа данных: символьный, целый и вещественный. Язык Си предполагает три размера целых значений и два размера вещественных. Для манипуляции отдельными битами и адресами значения могут использоваться как беззнаковые.
В языке Паскаль имеется четыре стандартных скалярных типа данных: булевский, символьный, целый, вещественный. Кроме того, программист имеет возможность конструировать новые скалярные типы путем перечисления всех возможных значений. Речь идет о скалярных перечисляемых типах. Например:
type day = (sun, mon, tue, wed, thu, fri, sat)
Значения нового типа будут представляться идентификаторами, которые будут константами этого нового типа. Теперь имеется возможность описания переменны нового типа:
var d1,d2: day
В Паскале имеется возможность конструировать новые скалярные типы данных путем выделения поддиапазона из одного ранее определенного скалярного типа данных за счет указания нижней и верхней границ этого поддиапазона.
Type
weekday = ( mon .. fri); { поддиапазон типа }
digit = ‘0’ . . ‘9’; {поддиапазон множества допустимых символов}
2.1.3. Символические константы.
В языке Си определение символической константы реализовано как макроопределение, обрабатываемое препроцессором транслятора с языка Си. Например
# define DAYS 29 { присваивается значение}
# define WEEK (DAYS /7 ) { присваивается значение выражения}
В языке Паскаль описание символической константы осуществляется с помощью служебного слова const. Например,
const имя = значение
Значения в описаниях символических констант могут быть любого из скалярных типов. Использовать выражения при описании символических констант в Паскале запрещается.
- Указатели
Указатели в языке Си могут указывать на объекты различных типов. В отличие от языка Си в языке Паскаль ссылки (указатели) используются только для доступа к динамическим объектам специфицированного типа. Ссылки не могут использоваться в Паскале для доступа к объектам, описанным явным образом.
Выделение и освобождение памяти не является частью языка Си, в то время как они являются частью языка Паскаль. При использовании Паскаля о выделении памяти для размещения некоторого объекта памяти заботится сам транслятор с языка Паскаль. При использовании Си ответственность за выделение памяти для размещения некоторого объекта возлагается на программиста, который должен явно указать размер выделяемой памяти, а это служит дополнительным потенциальным источником ошибок.
2.2. Операторы.
Управляющие конструкции в языках Си и Паскаль похожи, но есть некоторые отличия.
Имеющийся в Си оператор-переключатель switch обеспечивает нахождение необходимой ветви, выполнение списка операторов , соответствующего этой ветви, и списка операторов, соответствующих всем следующим за ней ветвям. Чтобы ограничиться лишь списком операторов, соответствующим найденной ветви, необходимо в качестве последнего оператора в этом списке использовать оператор завершения break, который обеспечивает выход из оператора -переключателя switch. Это является недостатком, поскольку ухудшает «удобочитаемость», надежность и модифицируемость программ, особенно в тех случаях, когда для различных альтернатив используются частично - перекрывающиеся фрагменты. В Паскале оператор варианта case обеспечивает выбор одной из взаимоисключающих альтернатив, что более удобно по сравнению по switch в Си. Однако case в Паскале не обеспечивает возможности выполнения некоторых действий, если среди ветвей отсутствует необходимая (такая возможность легко обеспечивается оператором-переключателем switch в Си с помощью служебного слова default ). Это неудобно, поскольку требует перед выполнение case явным образом выявлять наличие такой ситуации.
В языке Си отсутствует оператор цикла, аналогичный оператору цикла for в Паскале, в котором он гарантированно завершается, а направление изменения переменной цикла (увеличение и уменьшение) в нем определено лексически и число итераций известно заранее, т.е. до момента входа в этот оператор ( если только выход из этого оператора не осуществляется с помощью оператора перехода goto ). Эти свойства оператора цикла for в языке Паскаль улучшают «удобочитаемость» программ и облегчает их верификацию. К сожалению, приращение переменной цикла for в Паскале ограничено лишь значениями +1 и -1, что является серьезным неудобством.
В Паскале отсутствуют операторы безусловной передачи управления, аналогичные оператору завершения break и оператору продолжения continue в языке Си. Это вынуждает использовать оператор перехода goto или дополнительные переменные, обеспечивающие возможность выявления исключительных ситуаций. Кроме того, необходимо отметить недостаток оператора goto в языке Паскаль, связанный с тем, что в качестве меток используют не мнемонические обозначения, а целые значения без знака.
Неявное преобразование типов в процессе выполнения оператора присваивания в Паскале разрешено только в двух случаях - от типа с более узким диапазоном к типу с более широким диапазоном для ограниченных (интервальных) типов и от целого к вещественному. В Си неявное преобразование типов в процессе выполнения оператора присваивания разрешено всегда независимо от типов операндов в левой и правой частях оператора присваивания.
2.3. Структура программ.
Язык Паскаль навязывает жесткую последовательность расположения частей программы для обеспечения возможности проведения однопроходной трансляции. Тело программы располагается не непосредственно за описанием данных, а отделяется от него описанием процедур и функций. Это ухудшает «удобочитаемость» программ. В Си имеются лучшие средства структуризации программ. В частности, переменные могут быть описаны в начале любого блока, что стимулирует использование локальных переменных.
В отличие от Си в Паскале существует два типа подпрограмм - подпрограммы, возвращающие некоторое значение (функции), и подпрограммы, не возвращающие никакого значения (процедуры). Введение в Паскаль двух типов подпрограмм преследовало цель улучшения «удобочитаемости». Функции в Паскале могут возвращать значения любых скалярных типов или указатели, кроме значения структурированных типов. В языке Си функции могут возвращать значения любых типов, кроме массивов. В отличие от языка Си в Паскале допускается вложенность процедур и функций друг в друга.
В Паскале число фактических параметров должно быть равно числу формальных параметров, указанных при описании подпрограммы. В частности, невозможно написать подпрограмму, имеющую переменное число параметров. В языке Си можно написать функцию, имеющую переменное число параметров, но реализация таких функций, как правило, оказывается машинно-зависимой, что приводит к потере мобильности.
В отличие от Си в Паскале подпрограммы завершаются только в результате выполнения последнего оператора подпрограммы. Это соответствует философии структурного программирования, в соответствии с которой каждая языковая конструкция должна иметь ровно один вход и ровно один выход. Однако с практической точки зрения это оказывается не совсем удобно, поскольку требует использования оператора перехода goto.
Вопрос №31. Структурное программирование
Структурное программирование – это метод, предполагающий создание улучшенных программ. Он служит для организации проектирования и кодирования программ таким образом, чтобы предотвратить большинство логических ошибок и обнаружить те, которые допущены.
Структурное программирование включает три главные составляющие:
- проектирование сверху-вниз;
- модульное программирование;
- структурное кодирование.
Метод проектирования программ «сверху-вниз» вначале предусматривает
определение задачи в общих чертах, а затем постепенное уточнение структуры путем внесения более мелких деталей. Построение программы представляет собой последовательность шагов такого уточнения. Первоначально рекомендуется описать задачу на естественном языке. На каждом последующем шаге необходимо выявить основные функции, которые нужно выполнить, т.е. данная задача разбивается на ряд подзадач до тех пор, пока они не станут настолько простыми, что каждой из них будет соответствовать один модуль, который можно записать на алгоритмическом языке. Причем действие каждого модуля может быть описано одной фразой. Далее должны быть описаны данные, отмечены основные структуры и вид обработки данных. Каждый модуль должен иметь тестовые данные, описываемые вместе с модулем, которые впоследствии используются на этапе тестирования.
Модульное программирование – это искусство разбиения задачи на некоторое число модулей, умение широко использовать стандартные модули путем их параметрической настройки.
Структурное кодирование состоит в получении правильной программы из некоторых простых логических структур. Оно базируется на строго доказанной теореме о структурировании, которая утверждает, что любую правильную программу (с одним входом, одним выходом, без зацикливания и недостижимых команд) можно написать с использованием только следующих основных логических структур: линейная (следование), нелинейная (развилка) и циклическая (цикл, или повторение).
Комбинации правильных программ, полученные с использованием этих трех основных структур, также являются правильными программами. Причем каждая структура имеет один вход и один выход. Применяя итерацию и вложение основных структур, можно получить программу любого размера и сложности. При использовании только указанных структур отпадает необходимость в безусловных переходах и метках. Поэтому иногда структурное кодирование понимают в узком смысле как программирование без «GOTO».