
Методы и средства анализа безопасности программного обеспечения
| Вид материала | Документы |
- Рабочая программа учебной дисциплины (модуля) case-средства проектирования программного, 143.56kb.
- Программа-минимум кандидатского экзамена по специальности 05. 13. 19 «Методы и системы, 67.78kb.
- Кафедра системного анализа, 34.57kb.
- Программа «Математические проблемы защиты информации», 132.24kb.
- Направление 090305 «Информационная безопасность автоматизированных систем» Информационная, 17.19kb.
- § Модели угроз безопасности программного обеспечения, 158.47kb.
- Ейрокомпьютерные системы, технология разработки программного обеспечения, сети ЭВМ, 24.18kb.
- Information technology. Security techniques. Evaluation criteria for it security Security, 4433.86kb.
- Вопрос №3 Принципы проектирования информационного обеспечения программного комплекса, 2541.91kb.
- Программа вступительного экзамена в аспирантуру по специальной дисциплине 05. 20., 94.72kb.
7.6.Метод расчета вероятности наличия РПС на этапе испытаний программного обеспечения вычислительных задач
7.6.1.Постановка задачи
С точки зрения технологической безопасности тестирование должно позволять не только декларировать факт отсутствия в проверенных частях программных комплексов РПС, но и получать количественные характеристики, чаще всего вероятностные, существования таких дефектов в непроверенных программных компонентах. Данное утверждение справедливо для больших комплексов программ, полностью проверить все логические ветки которых не представляется возможным. К таким программам, в частности, можно отнести комплексы управления сложным технологическим процессом.
При исследовании сложных комплексов программ возникают существенные трудности использования известных методов детерминированного тестирования, связанные с необходимостью генерации входных наборов данных и расчета эталонных выходных данных. Использование метода стохастического тестирования упрощает генерацию входных данных, однако необходимость расчета эталонов сохраняется. Существенным при этом является то, что принципиально невозможно создать единый алгоритм расчета эталонов для различных тестируемых программ, что особенно характерно для программ, реализующих вычислительные алгоритмы.
Сущность вероятностного тестирования заключается в следующем. Исследуемая программа реализуется на наборах входных данных, представляющих собой случайные величины, распределенные по некоторому закону F(x). Для некоторого множества контрольных точек определяются вероятностные характеристики (ВХ) случайных величин, являющихся для этих точек выходными данными. Полученные ВХ сравниваются с эталонными ВХ, рассчитанными для данного закона распределения входных величин по заданному в спецификациях программы алгоритму, который данная программа реализует. В зависимости от степени совпадения экспериментально определенных ВХ с эталонными делается вывод об отсутствии в программе дефектов, преднамеренно внесенных на этапе ее создания. Необходимо отметить, что данный метод позволяет выявлять любые дефекты программы, в том числе и случайные ошибки. Однако использование стохастического тестирования наиболее целесообразно для тех участков сложных программных комплексов, для которых детерминированные методы требуют существенных по объему затрат на подготовку тестовых наборов данных. В то же время применение на этапе отладки программ более простых методов позволяет практически ликвидировать вероятность проявления случайных ошибок после завершения отладки и представления программного обеспечения на испытания.
Область применения метода вероятностного тестирования программ определяется в основном границами применимости математического аппарата, используемого для расчета эталонных вероятностных характеристик. Для программ, реализующих вычислительные функции, задача расчета вероятности наличия в программе РПС формулируется следующим образом [ЕУ].
Дано: алгоритм А, подлежащий реализации программой П, и требуемая достоверность результатов тестирования Р0 (вероятность наличия РПС в нетестируемых ветвях программы при заданном числе испытаний).
Требуется определить.
- последовательность законов распределения F1(x),...,Fn(x), j=1,..., входных величин Х={xj}, при которой с вероятностью Рпр гарантируется отсутствие в тестируемой программе РПС; при этом с вероятностью Р0 такие дефекты могут иметь место в нетестированных участках программы;
- множество контрольных точек (КТi), i=1,...,k, в которых определяется экспериментальное распределение выходных величин;
- множество Gi вероятностных характеристик, снимаемых с заданного множества КТ;
- множество величин Li таких, что если существует i, что
(Giэкс-Giэт>Li), то программа содержит дефекты с вероятностью Р0 или не содержит их с вероятностью Рпр.
Для решения данной задачи необходимо использовать методику, основанную на модификации метода вероятностного тестирования и позволяющую последовательно решить следующие частные задачи: определить множество информативных характеристик Gi случайных величин, снимаемых с некоторого множества КТi исследуемой программы; определить критерии принятия решения о наличии дефектов в программе П, обеспечивающих заданную достоверность такого решения.
7.6.2.Обоснование состава множества
информативных характеристик
Выбор информативных ВХ случайных величин Gi должен производиться с учетом двух основных факторов:
- выбранные ВХ должны существенно изменять свои значения при наличии в программе РПС;
- ВХ должны относительно легко вычисляться при экспериментальных исследованиях программы.
Поскольку информативные характеристики должны реагировать на наличие в программе закладок, изменяющих основной алгоритм функционирования или инициирующих изменение исходных данных (промежуточных или конечных результатов), следовательно, необходимо определить класс функций, которые получаются из исходной под воздействием программной закладки. К сожалению, РПС сами нуждаются в дополнительном исследовании и классификации, могут искажать реализуемую функцию в таком широком диапазоне, что однозначно предсказать ее искаженный вид просто невозможно. Поэтому для количественной оценки информативности той или иной ВХ целесообразно хотя бы приблизительно определить ожидаемый вариант воздействия дефекта на исследуемую программу.
С точки зрения удобства экспериментального вычисления наиболее простой характеристикой является значение функции распределения в одной точке. Вычисление этой характеристики сводится к подсчету значений выходной величины, попавших в заданный интервал. Вычисление этой ВХ для тех контрольных точек программы, где критерием перехода на ту или иную ветвь является значение функции, сводится к подсчету числа прохождений по этим ветвям. Например, экспериментальные исследования программ, входящих в специальное ПО, реализующего комбинационные алгоритмы выбора предпочтений, показали, что для программ такого класса частота прохождения различных ветвей при заданном законе распределения входных данных является достаточно устойчивой информативной характеристикой. Если при этом еще фиксировать временные интервалы прохождения различных путей программы, которые могут существенно отличаться друг от друга, то время выполнения также может использоваться в качестве информативной характеристики.
| ссылка скрыта BEST rus DOC FOR FULL SECURITY |
Для вычислительных программ, обладающих достаточно простой ациклической структурой, но реализующих сложные вычислительные функции, например, вычисления полиномов различной степени в приближенных расчетах, в качестве вероятностных характеристик могут использоваться начальные моменты законов распределения входных данных
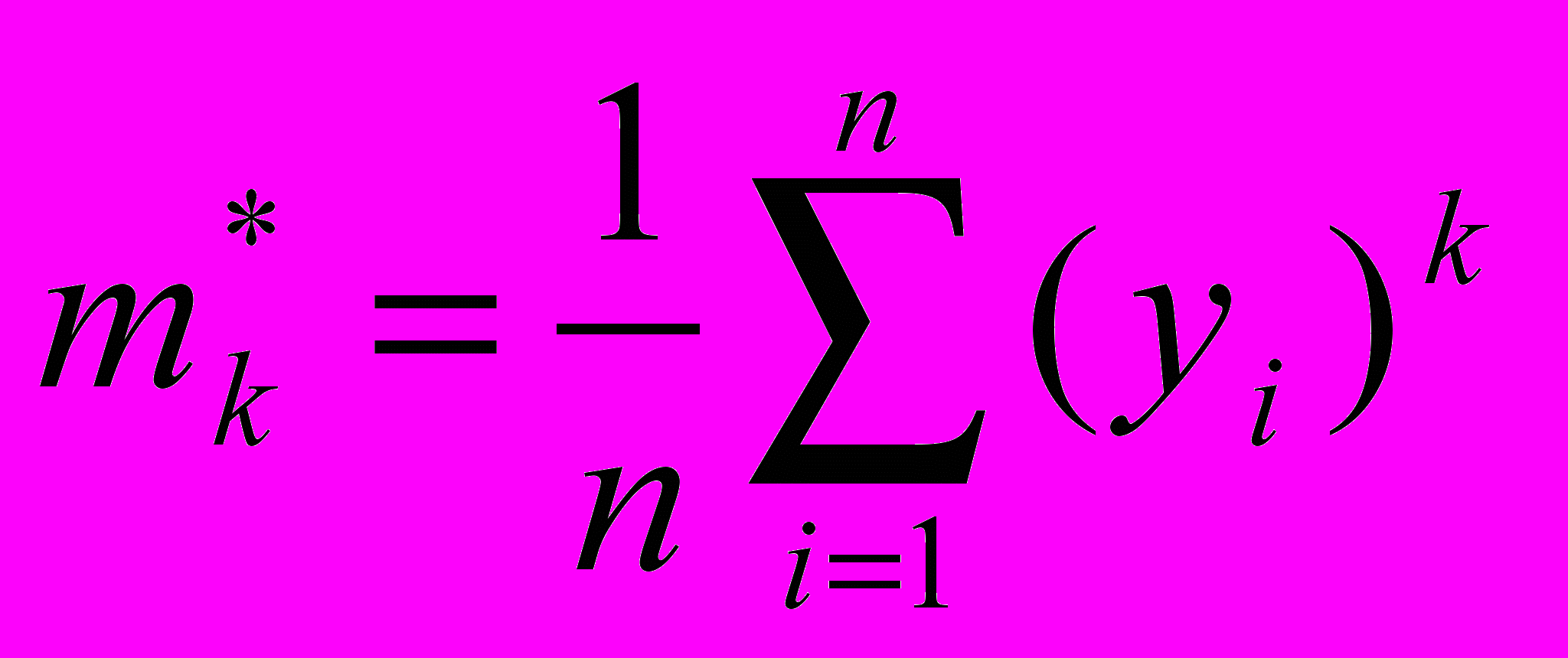
где yi - значения входной величины при i-том испытании (прогоне программы);
mk* - начальный момент, полученный при проверке программы;
n - число прогонов программы.
7.6.3.Алгоритмы приближенных вычислений вероятностных
характеристик наличия в программах РПС
В основу алгоритмов приближенных вычислений ВХ положен принцип расчета ВХ по функциям распределения выходных и промежуточных величин. При этом законы их распределения вычисляются как распределения функции от случайных аргументов [ЕУ].
Задача функционального преобразования непрерывных случайных величин формируется следующим образом.
Дано: совместная плотность распределения вероятностей wn(x1,...,xn) непрерывных случайных величин 1,...,n и совокупность функций f1,...,fm от n переменных. С помощью этих функций определены m случайных величин h1=f1(x1,...,xn),...,hm=fm(x1,...,xn), где xi – значения случайных величин i.
Необходимо: определить закон распределения каждой полученной случайной величины hj и их совместную плотность Wm(y1,...,ym), где yi - значения случайных величин hj.
Решение этой задачи точными методами [КК] даже для одномерного случая возможно только при жестких ограничениях на вид функции и закон распределения аргумента. Например, применение метода обратной функции требует вычисления на каждом участке монотонности f(x) обратной функции и производной от обратной функции.
Вычисление W(y) методом характеристической функции [КК] ограничено таким набором w(x) и f(x), для которых можно вычислить характеристическую функцию в явном виде, а по характеристической функции вычислить W(y).
В связи с этим целесообразно воспользоваться приближенным методом, сущность которого заключается в вычислении некоторых характеристик закона распределения и по ним восстановлении всего закона распределения. В качестве таких характеристик можно взять начальные моменты закона распределения:
mk(h)=
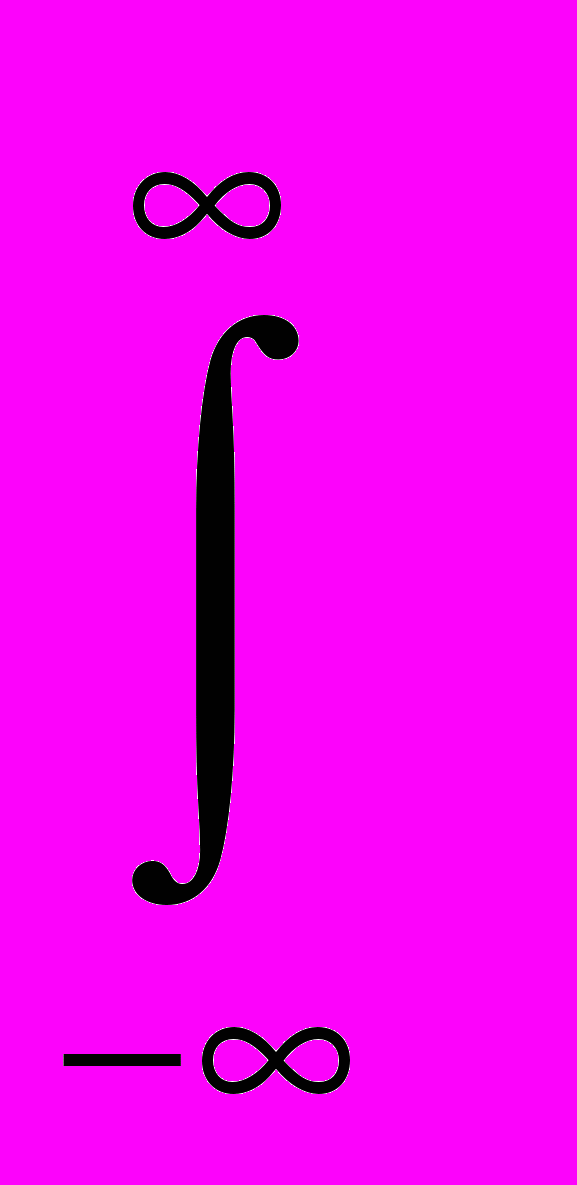 ...f(x1,...,xn)kw(x1,...,xn) dx1...dxn
...f(x1,...,xn)kw(x1,...,xn) dx1...dxnили для одномерного случая h=f(x)
mk(h)=
f(x)kw(x) dxпри условии, что этот интеграл сходится абсолютно [КК].
Поскольку данный методический подход возможен практически для любых вычислительных алгоритмов, то для иллюстрации его реализуемости можно ограничиться классом функций, представимых конечным степенным рядом. В этом случае если f(x)=
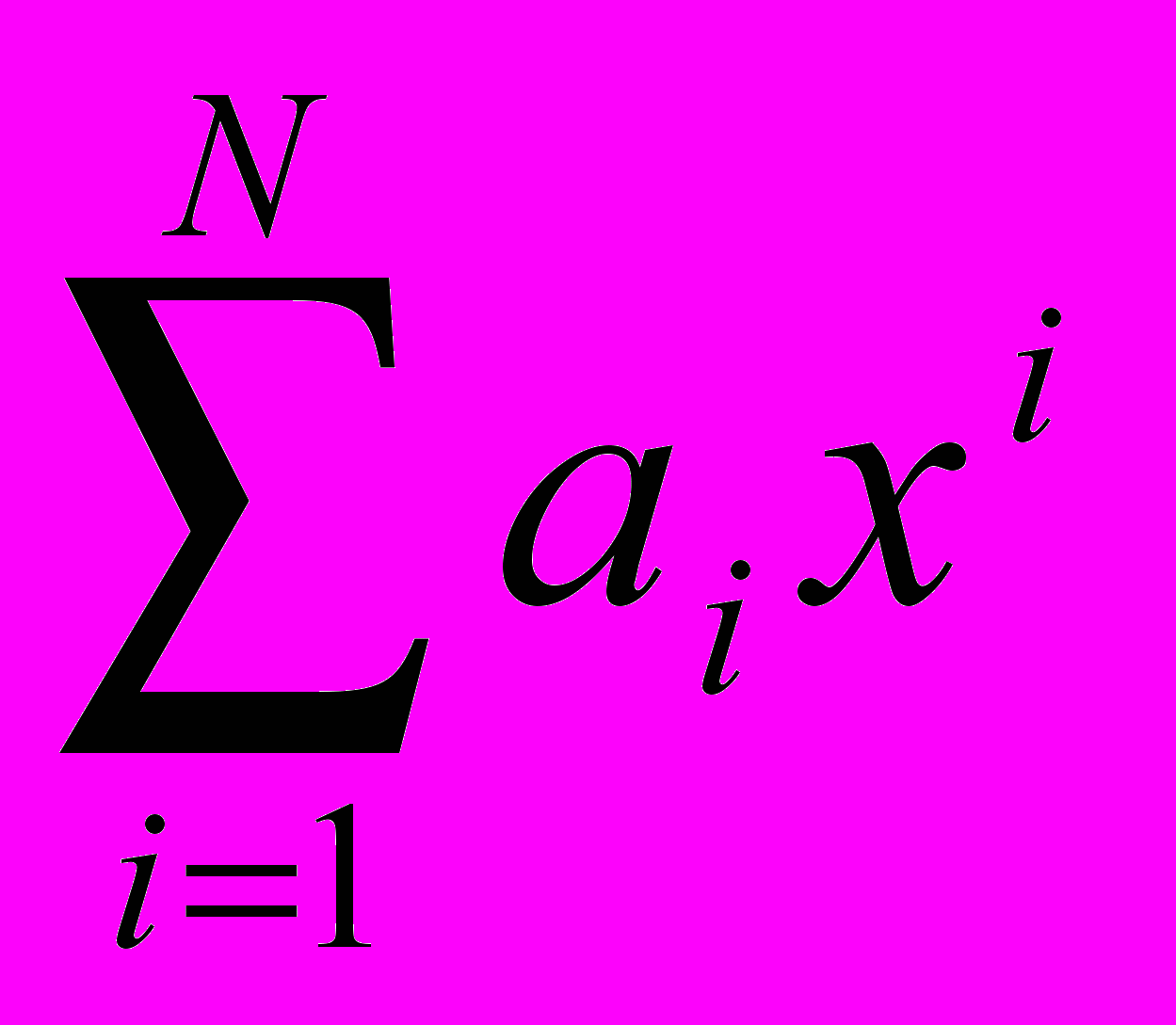 (общий вид), то определение первых t=r/N моментов случайных величин h=f(k) выполняется по следующему алгоритму (r – число первых начальных моментов закона распределения w(x), принимающих значения m1(),...,mr()).
(общий вид), то определение первых t=r/N моментов случайных величин h=f(k) выполняется по следующему алгоритму (r – число первых начальных моментов закона распределения w(x), принимающих значения m1(),...,mr()).Алгоритм A
А1. i:=1.
А2. Вычислить значения bj, j=1,...,N полинома f(x)i путем перемножения f(x)i и f(x)i-1: если f(x)=
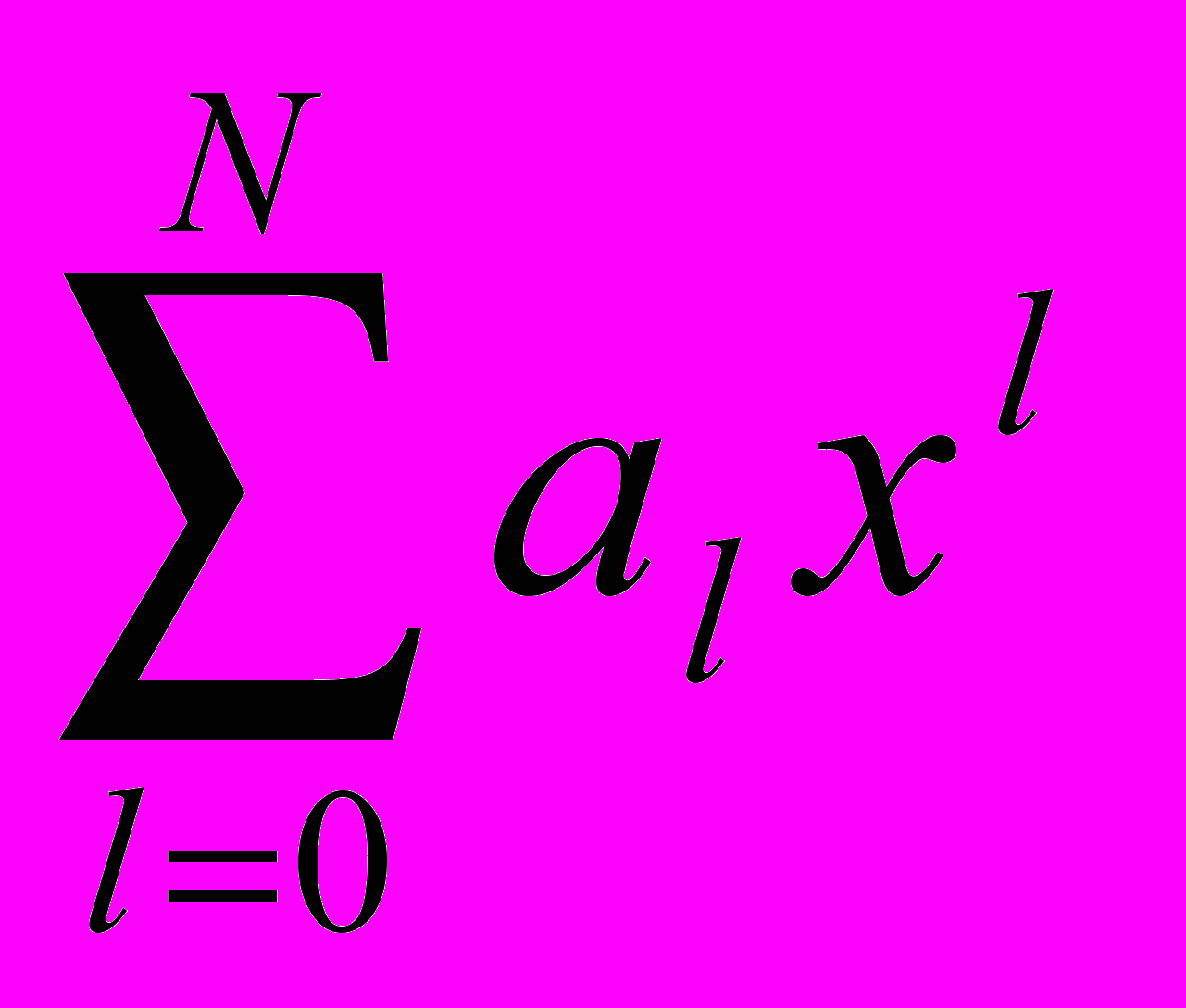 и f(x)i-1=
и f(x)i-1=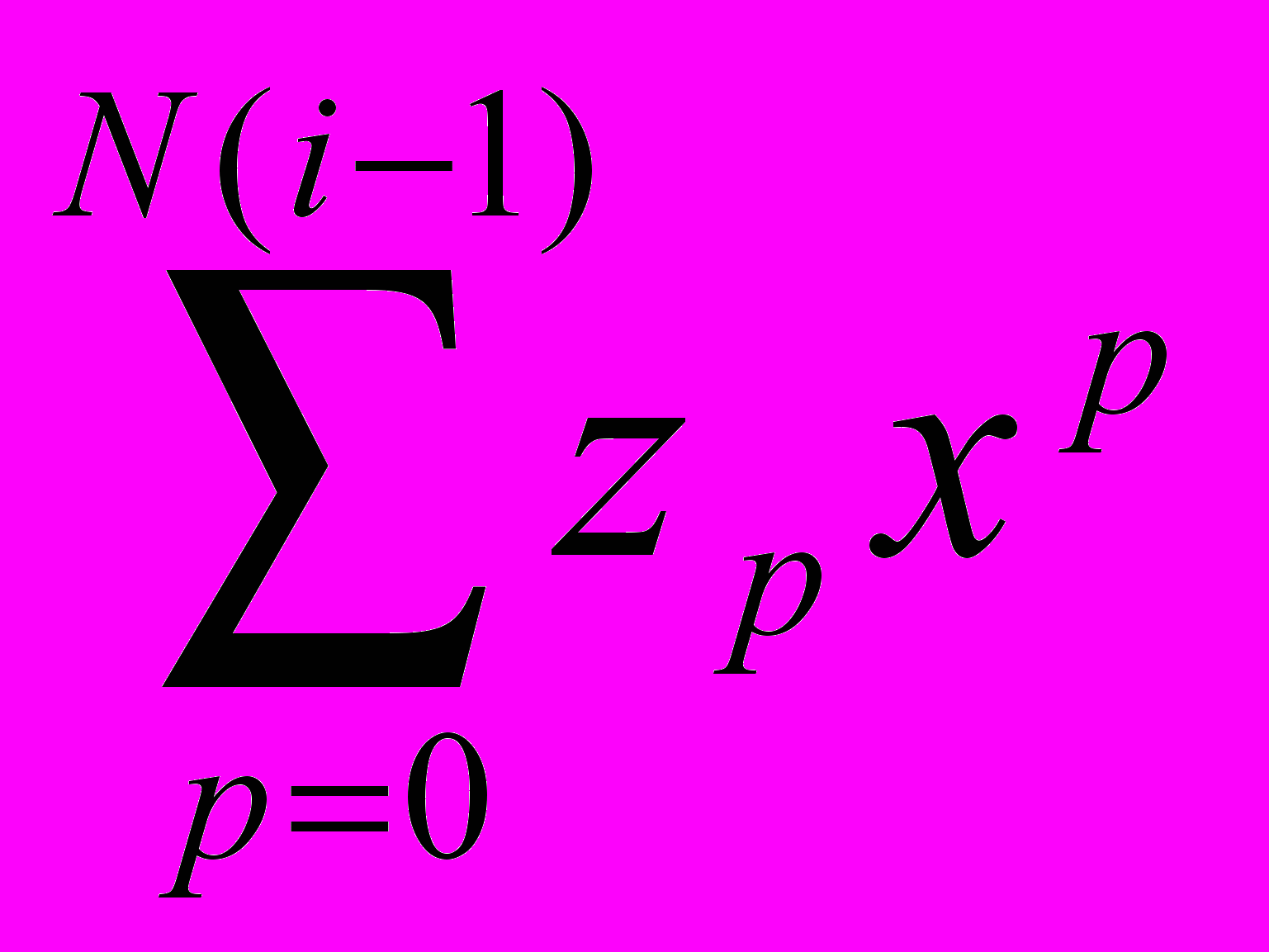 , то bj=
, то bj=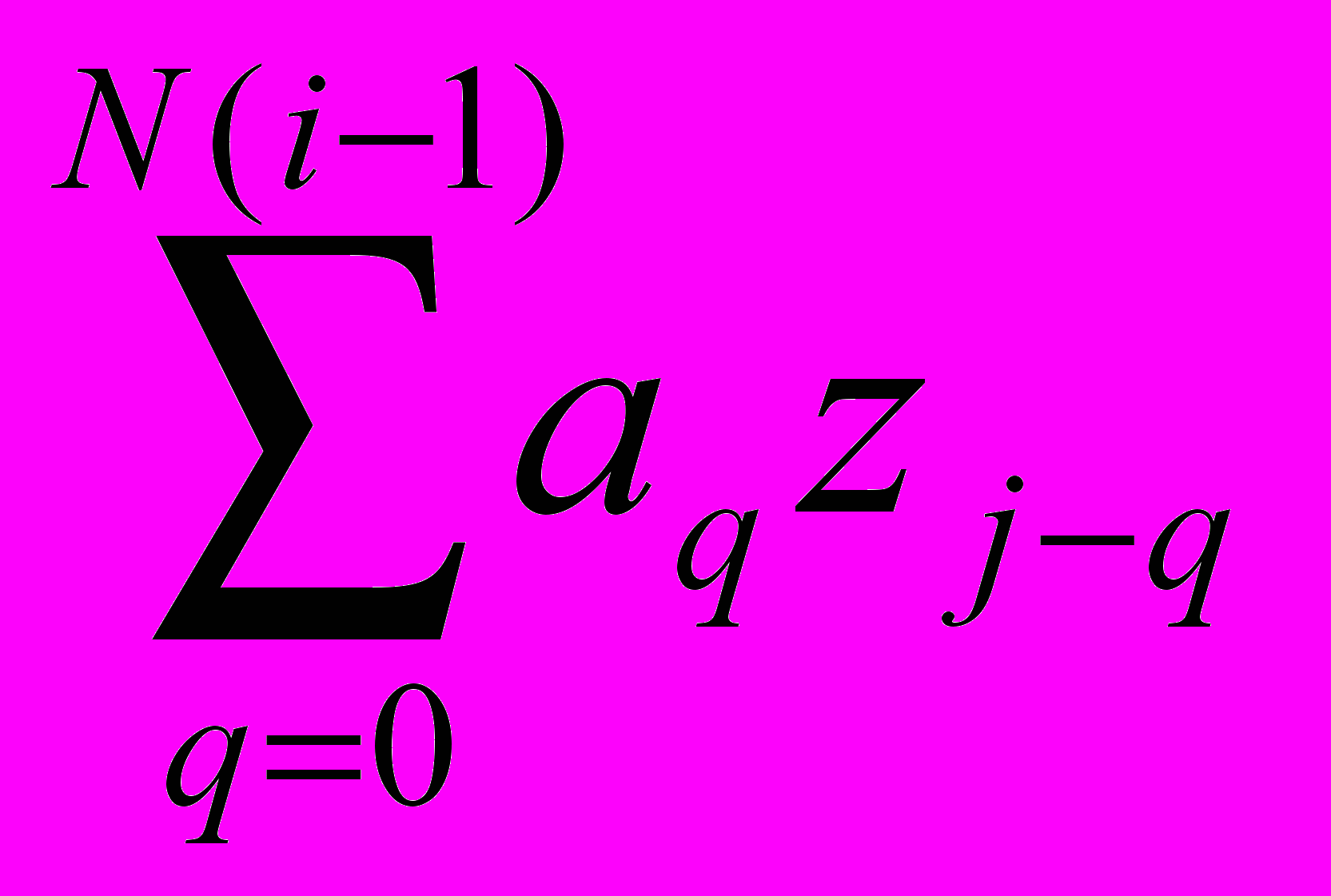 .
.А3. Вычислить mi(h)=
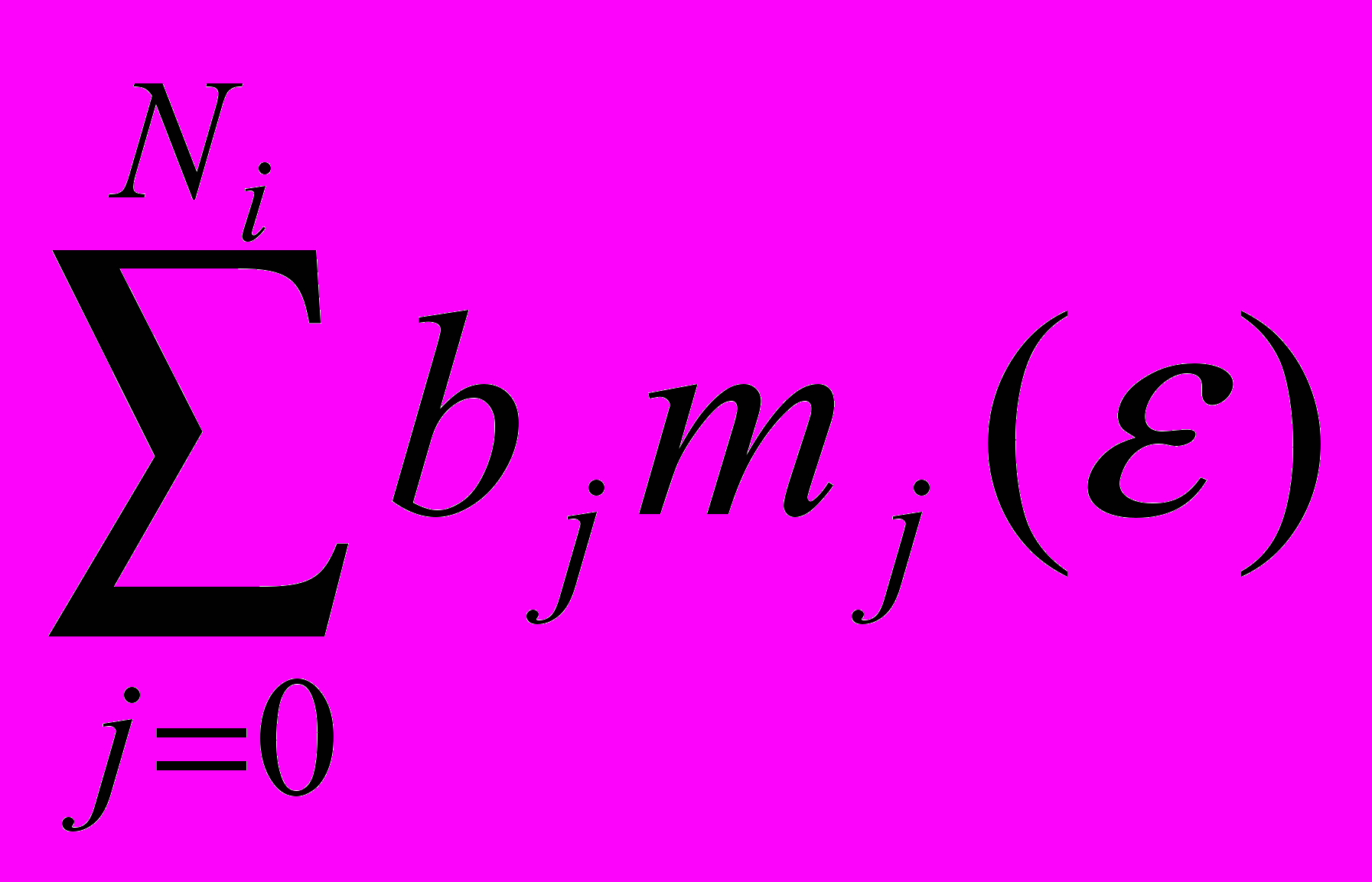 .
.А4. i:=i+1.
А5. Если ir/N, то переход на п.А2. В противном случае алгоритм завершается.
Кроме рассмотренного, возможно применение алгоритмов реализующих методы вычисления моментов функции от случайных величин с использованием моментопроизводящих или кумулянтных функций [КК].
Задача вычисления закона распределения F(y) в заданной точке y0 по L моментам формулируется следующим образом.
Дано: mi, i=1,...,L - начальные моменты F(y).
Необходимо: определить значения sup F(y0) и inf F(y0).
Метод вычисления sup F(y0) и inf F(y0) по известным начальным моментам F(y) описан в [Че]. Алгоритм вычисления sup F(y0) и inf F(y0) для L=2k-1, k=1,2..., и известных а и b – конечных значений y, меньше и больше которых соответственно значения функции принимать не могут, реализуют данный метод с некоторыми модификациями.
Алгоритм Б
Б1. Сформировать ряд «подходящих» дробей к интегралу
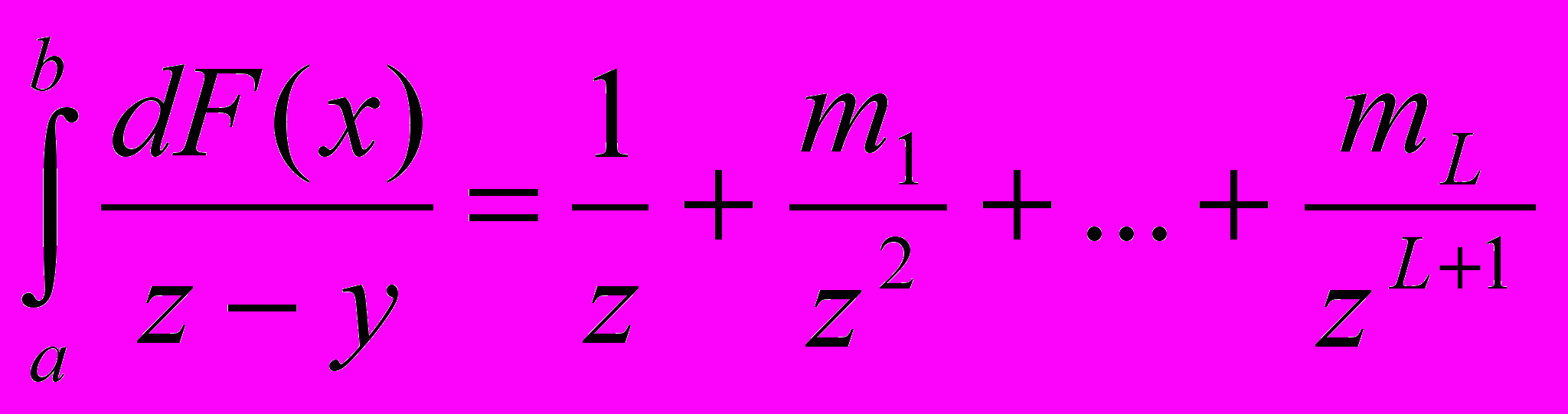
Б2. Преобразовать «подходящую дробь» в непрерывную вида
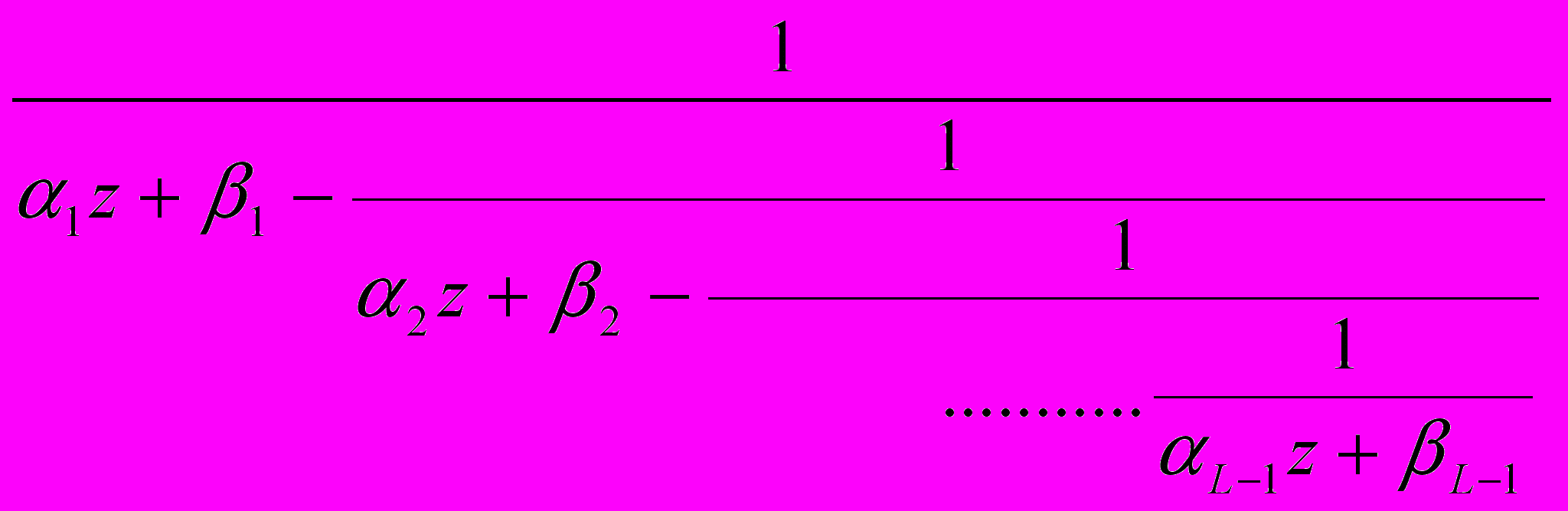 .
.Б3. Привести непрерывную дробь к дробно рациональному виду L(z)/L(z).
Б4. Выполнить пункты Б2 и Б3 для L=L-1 и вычислить
L-1(z)/L-1(z).
Б5. Определить функцию
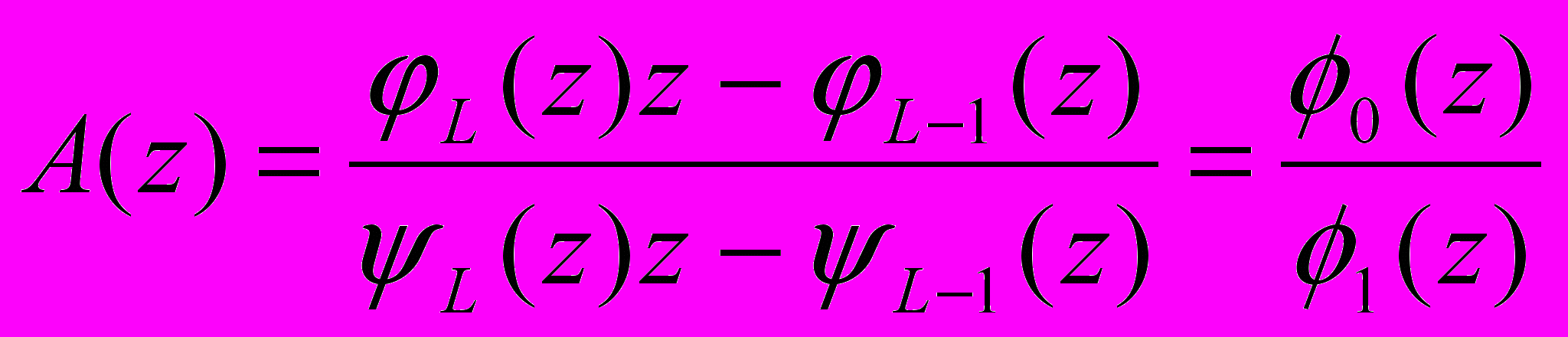 .
.Б6.Определить вещественные корни полинома 1(z).
Б7. Вычисление интеграла
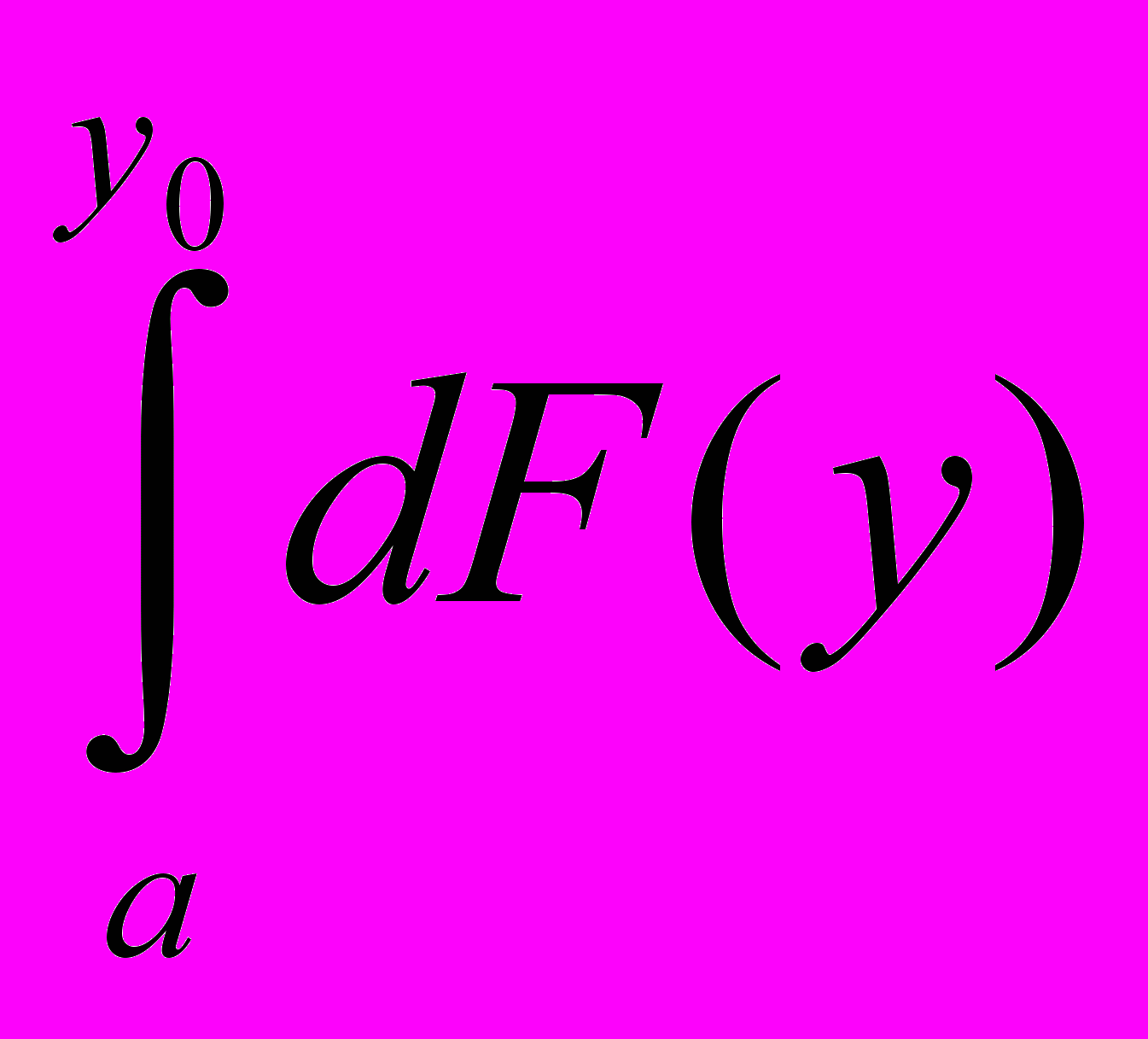 с помощью вычетов. При этом inf F(y0) будет равно сумме вычетов 0(z)/1(z) для всех y,y0, а sup F(y0), будет равно сумме inf F(y0) и очередного вычета. Среднее значение Fср(y0)=(sup F(y0)+inf F(y0))/2 и значение =(sup F(y0)+inf F(y0))/2, определяющее точность восстановления функции распределения, зависят от mi, i=1,...,L и y0. Однако 1/L+1.
с помощью вычетов. При этом inf F(y0) будет равно сумме вычетов 0(z)/1(z) для всех y,y0, а sup F(y0), будет равно сумме inf F(y0) и очередного вычета. Среднее значение Fср(y0)=(sup F(y0)+inf F(y0))/2 и значение =(sup F(y0)+inf F(y0))/2, определяющее точность восстановления функции распределения, зависят от mi, i=1,...,L и y0. Однако 1/L+1.Таким образом, с помощью алгоритмов А и Б можно с заданной точностью рассчитать вероятностные характеристики исследуемой программы.
7.6.4.Обоснование критериев принятия решения
о наличии в программе РПС
Задача выбора критериев наличия в исследуемой программе РПС в общем виде, формулируется следующим образом.
Дано:
- множество Gi вероятностных характеристик случайных величин, снимаемых с заданного множества контрольных точек;
- эталонные значения этих ВХ Gi* и их значения, полученные в результате n испытаний (прогонов) программы.
Необходимо: определить множество Li таких, что если существует i(Gi-Gi*>Li), то делается вывод о наличии в исследуемой программе РПС с вероятностью Р0.
Если в качестве информативной характеристики программы выбраны значения закона распределения выходной величины в точке y0, то задача определения решающих правил о наличии программных закладок может быть уточнена и записана в следующем виде.
Дано: Р=F(y0); q=1-P=P(y>y0); задано число прогонов программы n и значения доверительной вероятности Р0.
Необходимо: определить значение доверительного интервала L частоты появления события {A-yj<y0}, где yj - j-е значение выходной величины.
Для независимых испытаний частота появления события А-yi<y0 является случайной величиной, распределенной по биномиальному закону с математическим ожиданием Р и дисперсией D=Pq/n. Вероятность появления k событий при n испытаниях в этом случае рассчитывается по формуле Pk=CnkPkqn-k.
В качестве доверительного интервала [P1*,Р2*] целесообразно выбирать наименьший интервал, вероятность попадания за границы которого больше (1-Р)/2. Границы доверительных интервалов для различных значений Р, Р0 и n сведены в таблицы [Ве], что существенно облегчает задачу инженерного анализа результатов тестирования при контроле технологической безопасности программного обеспечения. С увеличением n биномиальное распределение будет стремиться к нормальному с теми же математическим ожиданием и дисперсией. При этом для вероятностного тестирования необходимо выбрать такие значения y0, чтобы Р0,5, что позволяет заменять биномиальное распределение нормальным с максимальной точностью. Доверительный интервал в этом случае определяется по формулам P(P-P*<Lэкс)=P0, Lэкс=arg Z*((1+P0)/2), где arg Z* - функция, обратная нормальной функции распределения Z*, полученная по таблицам.
С учетом того, что значение F(y0) вычисляется с точностью , доверительный интервал L=Lэкс+, то есть если при проведении испытаний значений Р* будет отличаться от аналогично рассчитанного на величину, большую, чем Lэкс+, то принимается решение о наличии в исследуемой программе РПС с вероятностью Р0.
Аналогичным образом доверительный интервал может быть определен и для случая, когда в качестве информативной характеристики программы используется математическое ожидание выходной случайной величины:
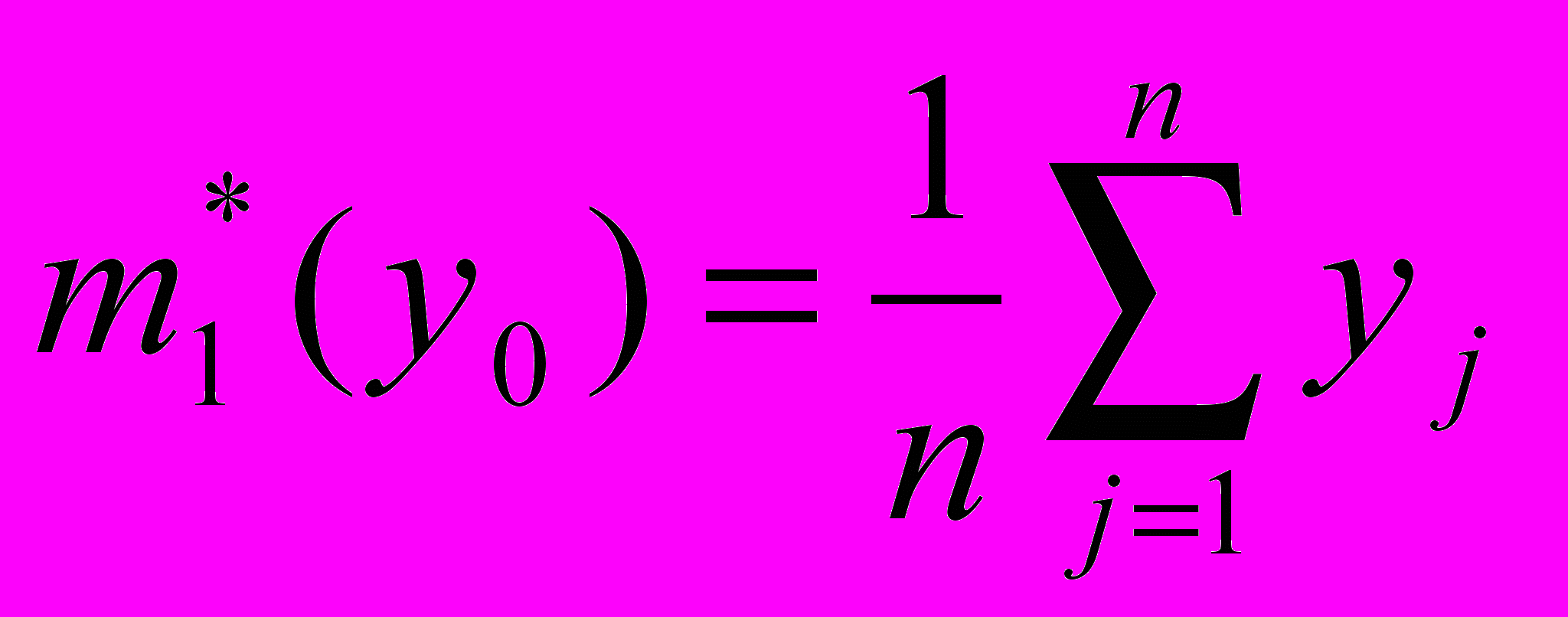 .
.Так как yj представляет собой случайные величины с одинаковым законом распределения, то законы распределения и их суммы стремятся к нормальному с математическим ожиданием m1(y) и дисперсией D(y)/n.
В этом случае доверительный интервал определяется по формуле Lэкс=arg Z*((1+P0)/2),
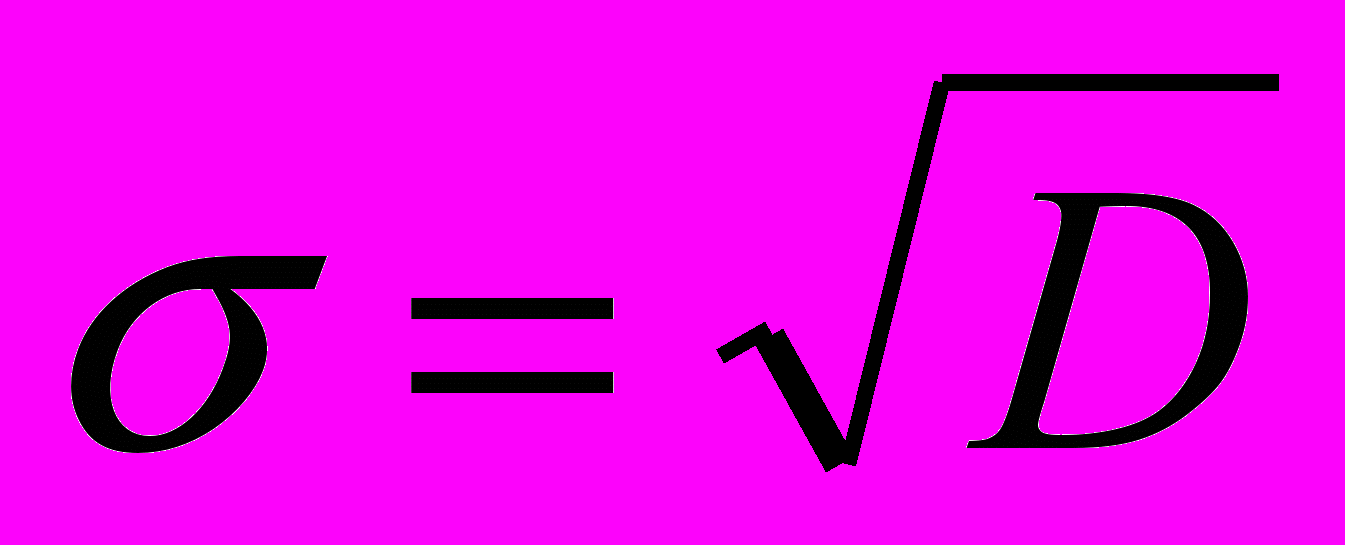 .
.Пользуясь методами математической статистики, можно аналогичным образом построить доверительные интервалы и для других ВХ. При этом факторы, влияющие на достоверность определения вероятности наличия в программном обеспечении РПС, можно разбить на три основные группы.
1. Точность аналитического вычисления ВХ. Если в качестве метода вычислений использовать метод моментов, то ошибки будут вызваны точностью представления реализуемой функции степенным рядом и ограниченным числом начальных моментов. Если функция представляется конечным степенным рядом или ошибка разложения в ряд достаточно мала, то можно считать, что точность вычисления ВХ будет зависеть от качества моментов. При заданной допустимой ошибке вычисления закона распределения требуемое число моментов может быть достаточно просто рассчитано.
2. Ограниченность числа испытаний (прогонов) программы. При известных значениях доверительного интервала с помощью методов статистики можно определить необходимое число испытаний, обеспечивающее достоверность результата не меньше Р0.
3. Закон распределения входных случайных величин. Для заданного закона распределения аргумента w(x) функции f1(x) и f2(x) будут неразличимы, если для каждой точки y
F(y)=
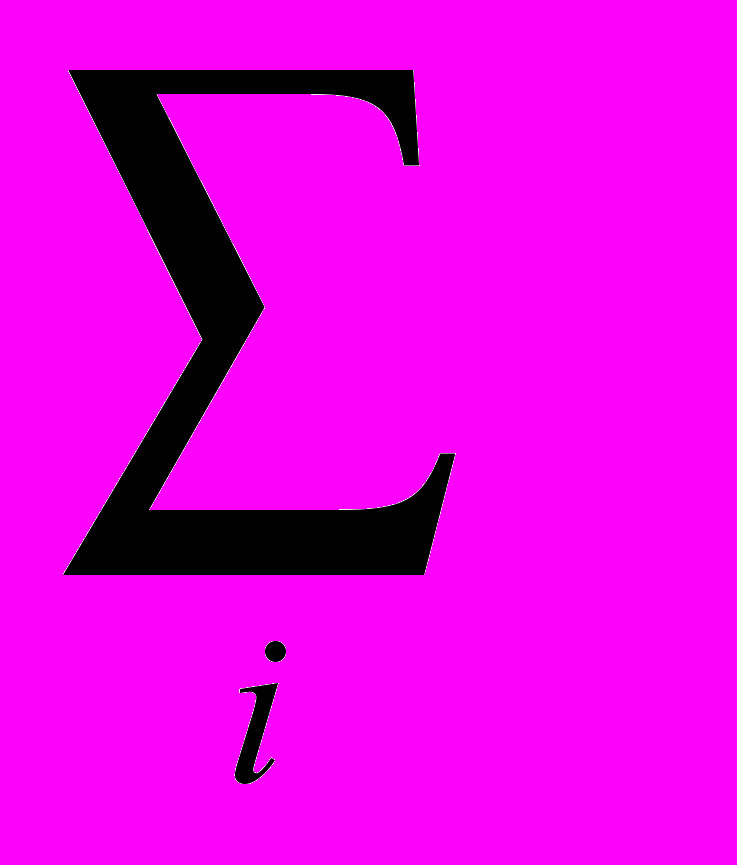
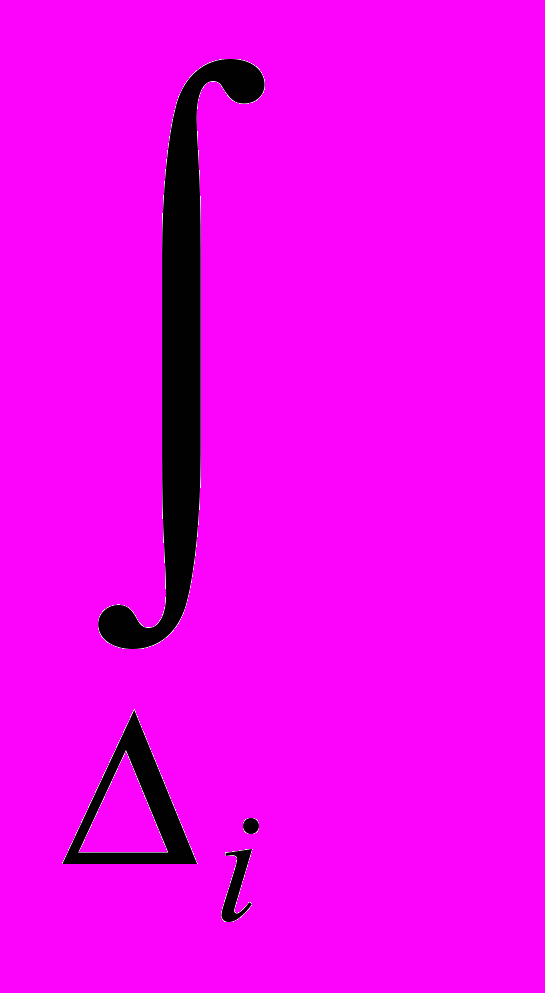 w(x) dx=
w(x) dx=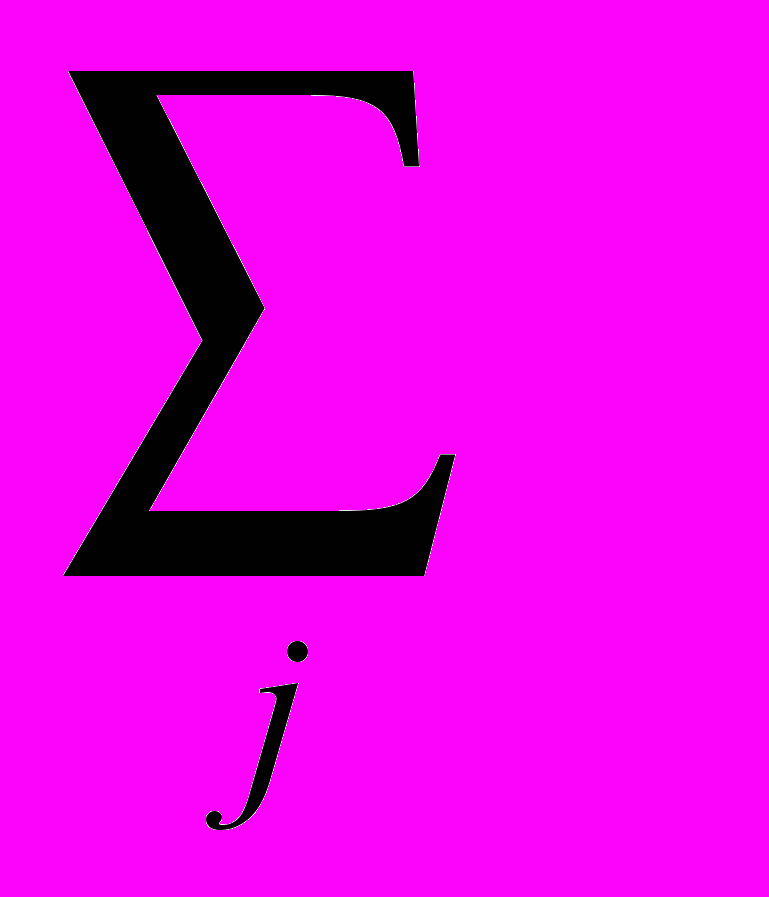
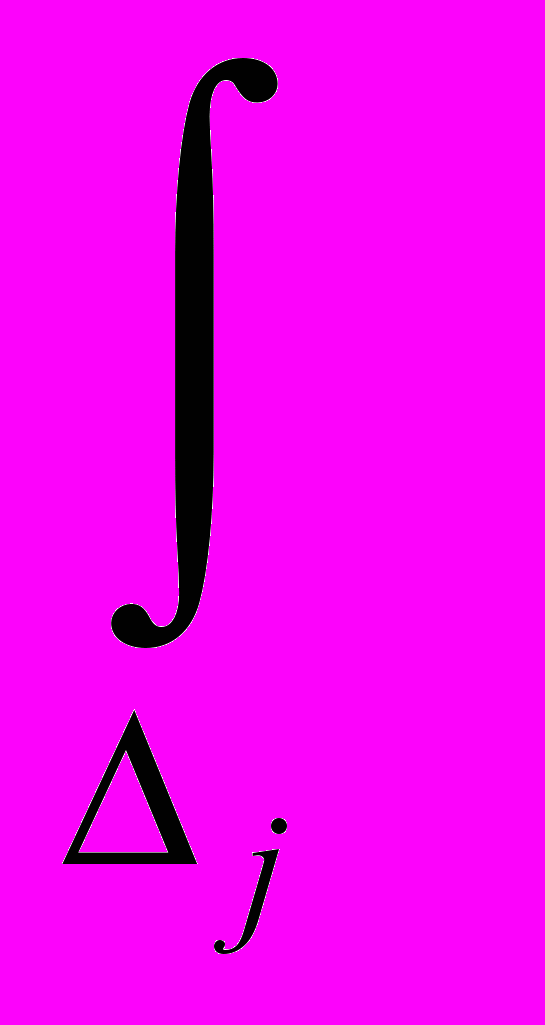 w(x) dx
w(x) dxили если задаться допустимой точностью вычисления функции распределения:
w(x) dx-w(x) dx,где i - интервалы аргумента, где f1(x)<y;
j - интервалы аргумента, где f2(x)<y.
Проверяя функции при различных законах распределения аргумента, можно сократить множество неразличимых функций. Для каждого класса допустимых функций можно найти такой набор законов распределения аргументов, который обеспечивает минимизацию области неразличимых функций.