
Рабочая программа по дисциплине Анализ и прогноз уровня загрязнения атмосферы, океана и вод суши Специальность 020804 геоэкология
| Вид материала | Рабочая программа |
- Утверждаю, 147.55kb.
- Основная образовательная программа высшего профессионального образования по направлению, 516.15kb.
- C. Исследование атмосферы и океана оптическими методами, 41.93kb.
- C. Исследование атмосферы и океана оптическими методами, 39.28kb.
- C. Исследование атмосферы и океана оптическими методами, 41.81kb.
- Уутверждаю, 205.02kb.
- А. Л. Чижевский Челябинск, 1943, 39.25kb.
- Рабочая программа по дисциплине «Учет и анализ банкротств» специальность 060500 «Бухгалтерский, 128.85kb.
- «Формы загрязнения природной среды. Загрязнители атмосферы, гидросферы, литосферы., 361.41kb.
- Геология месторождений полезных ископаемых специальность 020804 – геоэкология содержание, 54.54kb.
Введение
Подсистема обработки гидрохимической информации "Гидрохимия", позволяет реализовать на компьютере следующие функции:
1) внесение и корректировку данных о концентрации загрязняющих веществ в створах гидрохимических наблюдений;
2) получение справок, обобщающих имеющуюся в базе информацию в различных аспектах;
3) расчет характеристик качества воды.
Расчет характеристик качества воды выполняется по следующим методикам:
а) расчет индекса загрязненности воды согласно инструкции Госкомгидромета (ИЗВ);
б) расчет комбинаторного индекса загрязненности воды, основанного на методике Гидрохимического института (КИЗВ).
Первая используется при получении характеристик качества воды в створах по условию кратности превышения ПДК (для соответствующей категории водопользователя), а вторая - позволяет осуществить более объективную оценку качества воды и возможности ее использования на основании не только кратности превышения ПДК, но и частоты этого превышения. Оценочные таблицы по данным методикам приведены в прил. 1 и прил. 2.
Задание
Используя в качестве данных гидрохимических наблюдений значения табл. выполните оценку качества воды и загрязненности заданных водотоков с помощью ППП Гидрохимия.
Порядок работы:
- Найдите на жестком диске компьютера каталог HIM, войдите в него и запустите файл HIM.EXE. Выберите из главного меню пункт ВВОД. Произведите внесение и корректировку данных по концентрации загрязняющих веществ в створах гидрохимических наблюдений. Для этого достаточно задать код реки и выбрать клавишей INS из списка створов, представленного на экране дисплея, требуемый. Для заданного створа вводится: дата отбора пробы, расход воды реки, и концентрации ингредиентов.
- Выполните расчет характеристик качества воды используя подменю РАСЧЕТ главного меню.
- Используя подменю СПРАВКИ, получите справки о концентрации загрязняющих веществ. Все справки, результаты расчетов сохраняйте в файлы для создания отчета о выполненной работе.
- Войдите в меню ГРАФИКИ и постройте графики.
- В текстовом редакторе оформите отчет о выполненной работе.
Контрольные вопросы
- В чем отличие методики оценки качества воды по ИЗВ от КИЗ?
Приложение 1.
Оценочные таблицы к комплексной оценке качества воды на основе индекса загрязненности воды (ИЗВ)
Индекс загрязненности воды (ИЗВ) рассчитывается на основе наблюденных концентраций в j-ом контрольном створе в t-ый период времени – C[j,i,t] ,где i =1,N – индекс ингредиентов, N – количество ингредиентов, наблюдаемых в контрольном створе в t-ый период времени. Расчет ИЗВ в j-ом створе реки, Iz , проводится по формуле:
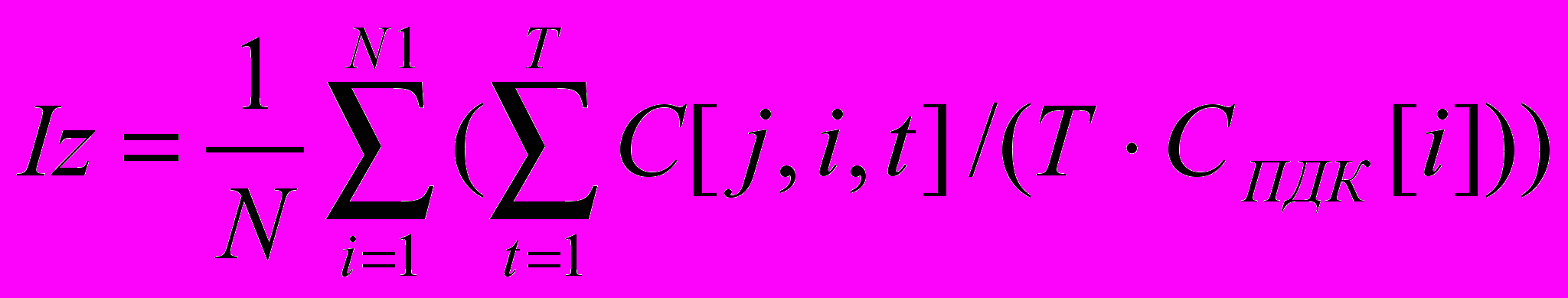 , ( 1 )
, ( 1 )где – N1 = 6 - количество выбранных для расчета ингредиентов, из которых обязательными являются растворенный О2 и БПК-5, а остальными - четыре первых ингредиента из ранжированного (по кратности превышения ПДК) убывающего ряда концентраций; T– количество значений i-го ингредиента за расчетный период; Cпдк[i] – предельно-допустимая концентрация i-го ингредиента.
Принадлежность качества воды водотока конкретному классу определяется сопоставлением значения соответствующему интервалу изменений значений ИЗВ. При этом различают следующие 7 классов :
| Iz | Класс качества воды | Характеристика уровня загрязненности |
| [0.0 ; 0.3) | 1 | ОЧЕНЬ ЧИСТАЯ |
| [0.3 ; 1.0) | 2 | ЧИСТАЯ |
| [1.0 ; 2.5) | 3 | УМЕРЕННО-ЗАГРЯЗНЕННАЯ |
| [2.5 ; 4.0) | 4 | ЗАГРЯЗНЕННАЯ |
| [4.0 ; 6.0) | 5 | ГРЯЗНАЯ |
| [6.0 ; 10.0) | 6 | ОЧЕНЬ ГРЯЗНАЯ |
| >=10.0 | 7 | ЧРЕЗВЫЧАЙНО-ГРЯЗНАЯ |
Статистическая связь между концентрациями и водностью (расходами) не учитывается.
Приложение 2.
Оценочные таблицы к комплексной оценке качества воды на основе комбинаторного индекса загрязненности воды (КИЗ)
Расчет значений КИЗ проводится согласно следующего алгоритма :
- Определяется кратность (уровень) превышения ПДК i-ым ингредиентом в j-ом створе реки:
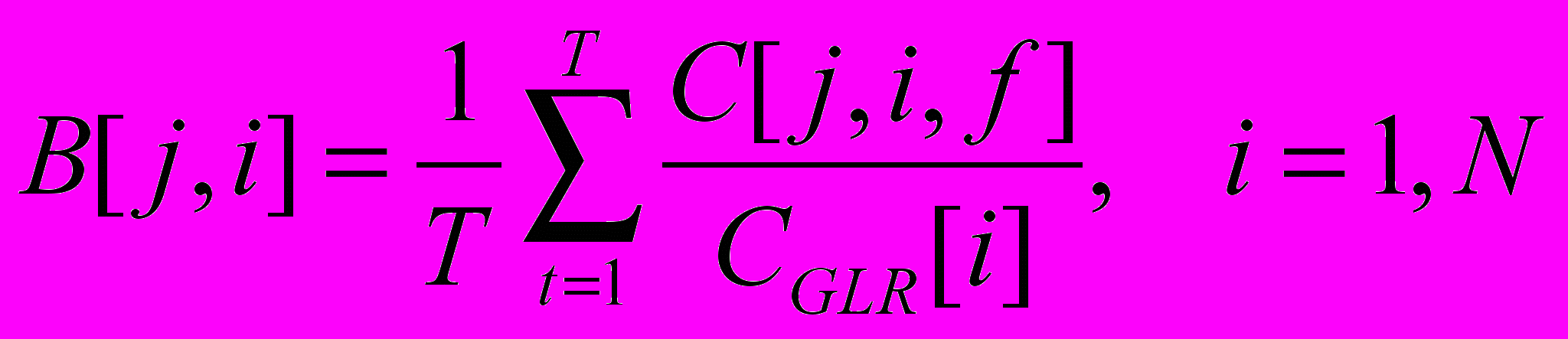 ( 2 )
( 2 )Cпдк[i] – предельно-допустимая концентрация i-го ингредиента.
По табл.1 определяется соответствующий оценочный балл Sb[j,i].
2. Определяется частота превышения i-го ингредиента ПДК в этом j-ом створе :
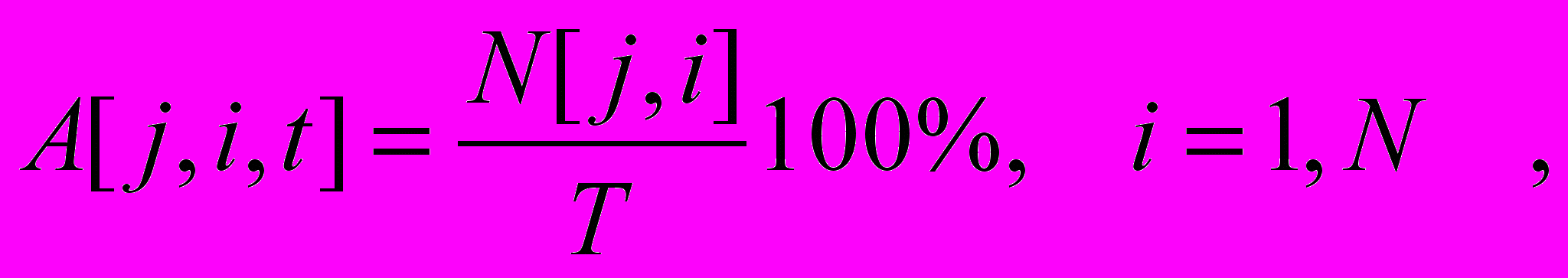 ( 3 )
( 3 )где: N[j,i] – количество превышений i -ой концентрацией Cпдк[i] за период наблюдений Т , т.е. количество раз выполнения неравенства:
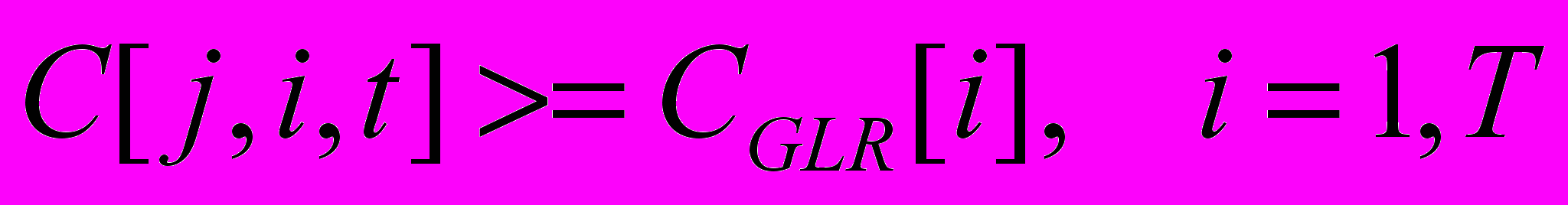 ( 4 )
( 4 )Т – общее количество наблюдений в j-ом створе за i-ой концентрацией ингредиента. По табл. 2 определяется частный оценочный балл Sa[j,i].
3. Определяется обобщенный комбинаторный индекс загрязненности (КИЗ) в j-ом створе i-ым ингредиентом:
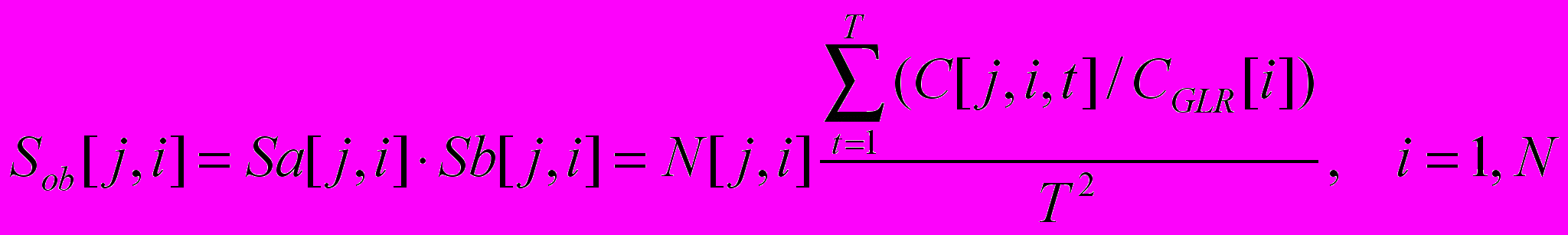 ( 5 )
( 5 )4. Определяется удельный комбинаторный индекс загрязненности воды (УКИЗ) в j-ом створе реки :
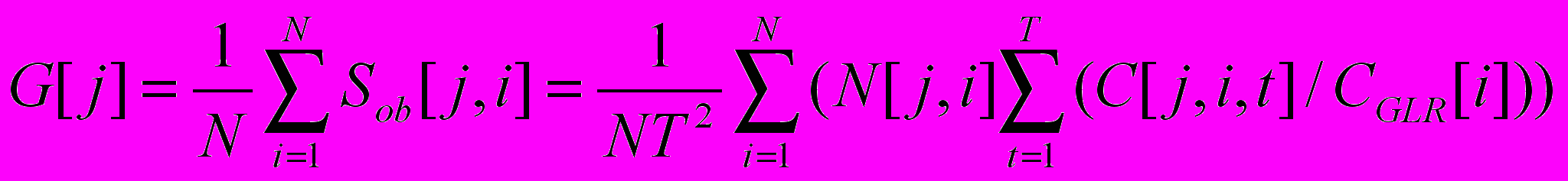 ( 6 )
( 6 )Рассчитанное значение G[j] сопоставляется с интервалами изменения УКИЗ, соответствующими различным классам качества воды, приведенными в табл. 3.
Значения частных оценочных баллов Sa[j,i] и Sb[j,i] приведены в табл. 1 и табл. 2.
Таблица 1 – Классификация воды водотоков по признаку повторяемости случаев загрязнения
| Интервалы повторяемости %, | Характеристика загрязненности воды по повторяемости | Интервалы частных оценочных баллов | Доля частного оценочного балла |
| [ 1;10 ) | единичная | [ 1;2) | 0,11 |
| [ 10,30) | неустойчивая | [ 2;3) | 0,05 |
| [ 30,50) | устойчивая | [ 3;4) | 0,05 |
| >=50 | характерная | 4 | 0,01 |
Примечание: установление конкретных значений баллов проводится по линейной интерполяции.
Таблица 2 – Классификация воды водотоков по уровню загрязненности
| Интервалы кратности превышения ПДК | Характеристика уровня загрязненности воды | Интервалы частных оценочных баллов | Доля частного оценочного балла |
| [1;2) | низкий | [1;2) | 1,0 |
| [2;10) | средний | [2;3) | 0,125 |
| [10,50) | высокий | [3,4) | 0,025 |
| 50 | очень высокий | 4 | 0,01 |
Примечание: Установление конкретных значений баллов проводится по линейной интерполяции.
Таблица 3 – Классификация качества воды по критерию КИЗ (УКИЗ)
| Класс качества воды | Описание класса | Величина комбинаторного индекса загрязненности воды (КИЗ) | |||||
| При отсутствии критических :показателей ( A = 0 ) | При наличии критических показателей (КПЗ) | ||||||
| 1 КПЗ (A = 0.9) | 2 КПЗ (A = 0.9) | 3 КПЗ (A = 0.9) | 4 КПЗ (A = 0.9) | 5 КПЗ (A = 0.9) | |||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 2 | Очень чистая | ( 0.1 ) | - | - | - | - | - |
| 3 | чистая | 1 | 0.9 | 0.8 | 0.7 | 0.6 | 0.5 |
| 4 | Умеренно- загрязненная | ( 1.3 ] | (0.9; 2.7] | (1.6; 2.4] | (1.4; 2.1] | (1.2; 1.8] | (1.0; 1.5] |
| 5 | Загрязненная | ( 3.4 ] | (2.7; 3.6] | (2.4; 3.2] | (2.1; 2.8] | (1.8; 2.4] | (1.5; 2.0] |
| 6 | грязная | ( 4.10 ] | (3.6; 9.0] | (3.2; 8.0] | (2.8; 7.0] | (2.4; 6.0] | (2.0; 5.0] |
| 7 | Очень грязная | > 10 | >9.0 | >8.0 | >7.0 | >6.0 | >5.0 |
ПРИМЕЧАНИЕ: критические показатели загрязненности определяются по выборке концентраций ингредиентов в контрольном створе по величине кратности превышения ПДК и частоте этого превышения. КПЗ являются теми ингредиентами, наблюденные значения которых, переводят воду по степени загрязненности в класс "очень грязная". A - коэффициент повышающий расчетную степень загрязненности воды в зависимости от числа КПЗ.
В качестве КПЗ выбираются те ингредиенты, для которых повторяемость случаев загрязнения
"устойчивая" или "характерная" и уровень загрязненности – "высокий" или "очень высокий".
ЛАБОРАТОРНАЯ РАБОТА № 5
Тема: Моделирование загрязнения вод суши.
Продолжительность 4 часа
Задание:
Используя программу РЕКА определить
- На каком расстоянии от устья реки возможен сброс промышленных вод предприятия с сохранением в устье реки качества вод не превышающем ПДК. Предусмотреть случай уменьшения расхода реки на 30% (Табл.1).
- Определить загрязнение реки на заданном километре от устья в результате сбросов группы предприятиятий. Оценить “вклад” в загрязнение каждым предприятием (Табл.2).
Расчеты основаны на "Методике расчета предельно допустимых сбросов (ПДС) веществ в водные объекты со сточными водами", ВНИИВО, Харьков 1990 г.
Модель водного объекта имеет следующий вид
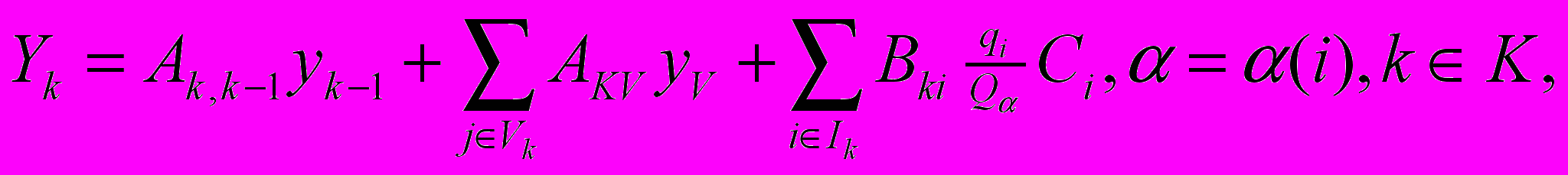 (*)
(*)где К – множество номеров расчетных створов, в которых моделируется качество воды; Yk – вектор показателей (концентраций веществ), характеризующих качество воды в створе k, г/м3; Yk-1 – то же для предшествующего по течению створа k-1 (если (k-1)
 K, то створ k-1 является начальным створом (истоком) реки и Y k-1 =(Сφ)k1, где (Сφ)k1 – вектор фоновых концентраций веществ в воде водотока в створе k-1, (г/м3); Yν – то же для створа ν, расположенного в устье притока, впадающего на участке (k,k-1); Сi – вектор максимальных среднечасовых концентраций веществ в сточных водах выпуска i, (г/м3); qi- расход сточных вод выпуска i, (м3/с); Qα- расход воды реки в расчетной секции α, (м3/с);α(i)- номер расчетной секции, в начале которой расположен выпуск сточных вод водопользователя i, (м3/с); Vk – множество номеров створов, расположенных в устьях притоков, впадающих на участке (k,k-1); Ik – множество номеров выпуска сточных вод, поступающих в водный объект на участке (k,k-1); Ak,k-1 , Akv и Bki - матрицы, характеризующие разбавление и трансформацию качества речных и сточных вод;
K, то створ k-1 является начальным створом (истоком) реки и Y k-1 =(Сφ)k1, где (Сφ)k1 – вектор фоновых концентраций веществ в воде водотока в створе k-1, (г/м3); Yν – то же для створа ν, расположенного в устье притока, впадающего на участке (k,k-1); Сi – вектор максимальных среднечасовых концентраций веществ в сточных водах выпуска i, (г/м3); qi- расход сточных вод выпуска i, (м3/с); Qα- расход воды реки в расчетной секции α, (м3/с);α(i)- номер расчетной секции, в начале которой расположен выпуск сточных вод водопользователя i, (м3/с); Vk – множество номеров створов, расположенных в устьях притоков, впадающих на участке (k,k-1); Ik – множество номеров выпуска сточных вод, поступающих в водный объект на участке (k,k-1); Ak,k-1 , Akv и Bki - матрицы, характеризующие разбавление и трансформацию качества речных и сточных вод;Порядок работы:
- Входим в директорию РЕКА и запускаем файл peka.exe.
- С помощью кнопок "Река" и "Вариант" выбираем реку с которой будем работать. Кратко работу с программой можно пояснить так: вначале подготавливаются (редактируются) исходные данные для моделирования, затем запускается расчет и анализируются результаты либо в табличной, либо в графической форме с выводом на экран, либо на принтер.
- Прежде чем запустить расчет загрязнения необходимо подготовить таблицу гидросети исследуемого водотока, таблицу источников сбросов загрязняющих веществ, таблицу притоков, таблицу загрязняющих веществ. Для этого выберите меню "Таблицы", затем из списка таблиц выберите название редактируемой таблицы.
Таблица "Гидросеть" определяет графический вид гидросети (Меню Схема) и определяет гидрологические параметры моделирования.
Добавить новую строку можно нажатием клавиши “Ins”, а удалить строку нажатием клавиши “Del”.
Поля "Река" и "Вариант" при добавлении новой строки заполняются автоматически текущими значениями. Поле "Характеристика" может принимать следующие значения:
л.с. - насел.пункт на левом берегу реки
п.с. - насел.пункт на правом берегу реки
л.р. - левый приток реки
п.р. - правый приток реки
сбр. - источник сброса
В поле "Расстояние, км" задается расстояние от точки начала водотока (принимается за 0 км) до описываемого в данной табличной строке створа.
Скорость и расход воды в основном водотоке на уровне данного створа заносятся в поля "Скорость, м/с" и "Расход, л/c".
Если в таблице "Гидросеть" изменить поле "Река" или "Вариант" или и то и другое, то при сохранении Таблица с новым сочетанием "Река" и "Вариант" заменит Таблицу "Гидросеть" со старыми значенпиями "Река" и "Вариант". Будьте внимательны !
Поля "Код реки" и "Номер ист.сбр." являются вспомогательными, их можно не вводить.
Таблица "Притоки" аналогична таблице источников сбросов.
Для удаления строки из таблицы "Загрязняющие вещества" достаточно поставить в поле "Выбор" данной строки "-". После выхода из редактирования (Клавиша "Esc") с сохранением результата и повторного входа в данную таблицу этой строки уже не будет.
- Запуск режима "Моделирование" формирует таблицу "Результаты моделирования". Количество загрязняющих веществ и их состав определяются исходной таблицей "Загрязняющие вещества" для выбранной реки и варианта. Сохраняется только последний вариант таблицы "Результаты моделирования", то есть новая таблица "Результаты моделирования" стирает старую таблицу
- Режим "Схема" формирует и выводит слева на экран графическое представление гидросети реки и справа графики концентраций загрязняющих веществ. Для перемещения схемы и графиков вниз, вверх, вправо, влево по экрану необходимо поместить курсор мыши в крайнее положение на экране (вниз, вверх, вправо, влево) и щелкнуть левой кнопкой мыши. При этом изображение сдвинется в сорону противоположную от курсора.
- Режим "Печать" позволяет распечатать таблицы на принтере и редактировать эти таблицы в текстовом редакторе Лексикон не выходя из программы РЕКА.
Контрольные вопросы
- Приведите основные расчетные условия используемые при моделировании загрязнения вод суши с помощью программы РЕКА.
- Какие исходные данные необходимы для выполнения расчета загрязнения поверхностного водотока с помощью программы РЕКА?
- Что такое коэффициент неконсервативности загрязняющего вещества?
- К какому классу моделей относится используемая модель водотока?
ЛАБОРАТОРНАЯ РАБОТА № 7
Тема: Пространственное моделирование и анализ в ГИС ArcView
Продолжительность 4 часа
Задание: Выполните пространственный анализ закономерностей между критериями состояния здоровья (фактор-отклик) и критериями качества среды обитания (факторы риска) используя банк данных ГИС г. Саранска и ГИС ArcView 3.1 (модуль Spatial Analyst).
Порядок работы:
На рис. 1 представлены этапы построения гистограммы среднего значения фактора-отклика по зонам фактора риска1 и гистограммы среднего значения фактора-отклика по зонам расстояний фактора-риска2.
- Из среды Windows запустите ArcView.
- Создайте новый Вид. Используйте кнопку New в окне проекта Untitled при выбранной закладке Views.
- Задайте рабочий каталог, т.е. каталог куда будут записываться все создаваемые данные. (File-Set Working Directory). Обычно там, где находятся исходные файлы.
- Добавьте в Вид необходимые Темы (View-Add Theme) представленные shp-файлами.
- Сохраните проект, задав ему уникальное имя (File-Save Project as). Помните, что сохранив проект, вы можете в любой момент, открыть его и увидеть все, что было на экране на момент его сохранения на диске.
- Подключите к вашему проекту таблицы (Окно проекта-закладка Tables-ADD).
- Щелкните по Теме Clinic, чтобы сделать ее активной. Откройте Атрибутивную Таблицу Темы Clinic (кнопка Open Theme Table).
- Чтобы показать заболеваемость необходимо присоединить Таблицу bol98.dbf, содержащую данные по 21 заболеваемости (поля bol1..bol21) через поле Site - номера педиатрических участков с полем Clinic Атрибутивной таблицы темы Clinic, также содержащей номера педиатрических участков.
- Откройте в Виде одновременно эти две таблицы. Отметьте соединяемые поля. Активной должна быть атрибутивная таблица Темы Clinic. Для объединения таблиц нажмите кнопку Join (Объединить).
- Для этого дважды щелкните по Clinic в легенде, чтобы войти в редактор легенды (Legend Editor).
- Задайте тип легенды (Legend Type) градуированная шкала (Graduated Color) и задайте атрибут, отображаемый в теме (Classification Field).
- Нажмите кнопку применить (Apply) и закройте редактор легенды.
- Для построения Темы фактора риска скорее всего Вам придется построить Тему по ряду нерегулярных точек наблюдений, представленных DBF-файлом с координатами этих точек.
- Перейдите в окно Вида. Добавьте данные как Тему Событий из меню View-Add Event Theme.
- В следующем окне, в ниспадающем списке Table укажите необходимую таблицу, убедитесь, что компьютер правильно понял, где находятся координаты точек (X-field, Y-field). Нажмите Ok..
- Высветите добавленную Тему и сделайте ее активной.
- Построим по новой Теме интеполяционную Grid-тему (Surface-Interpolate Grid).
- В следующем окне задайте Экстент создаваемой Grid-темы (Output Grid Extent) и размеры ячеек, указав либо величину стороны ячейки (Cell Size) либо количество строк (Number of Rows) и столбцов (Number of Columns) Grid-темы.
- В следующем окне задайте метод (Method) Spline, укажите поле исходной таблицы по которому создается Grid-тема (Zvalue Field). Задайте Тип (Type) Tension. Нажмите Ok.
- Щелкните по квадратику в легенде, чтобы высветить Grid-тему. Сделайте ее активной. Отредактируйте если необходимо легенду.
- Для создания зон в Grid-теме выполните переклассификацию (Analysis-Reclassify).
- В диалоговом окне нажмите кнопку classify и задайте число зон (Number of classes). Нажмите Ok. Отредактируйте легенду полученной темы.
- Сделайте переклассификациированную тему активной. И наконец, долгожданный анализ по зонам (Analisys-Summarize Zones). В диалоговом окне выберите поле, задающее зоны во входной теме зон. Нажмите Ok.
- Из ниспадающего списка выберите Grid-тема значений, задающую значения ячеек для суммирования внутри каждой зоны Темы зон. Нажмите Ok. Выберите из ниспадающего списка статистику для построения диаграммы (возможны: площадь, минимум, максимум, среднее (mean) и др. ). Нажмите Ok.
- Повторите шаги 12-14 для подключения в Вид Темы фактора риска2.
- Постройте Grid-тему расстояний от источников фактора риска2 (Find Distance).
- Выполните зонирование расстояний (аналогично шагам 19-20).
- Постройте гистограмму фатора-отклика по зонам расстояний фактора-риска2.
- Оцените полученные гистограммы. Подготовьте отчет.


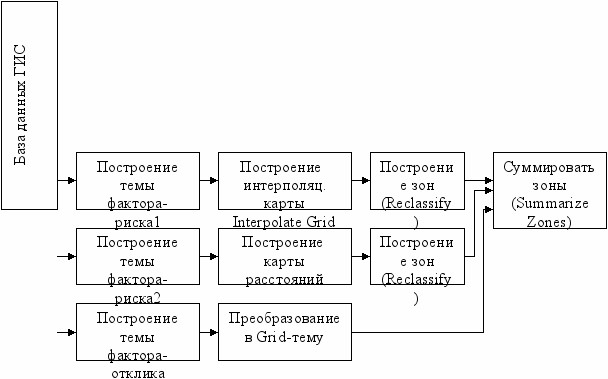
Рис. 1. Блок-схема выполнения задания.
Контрольные вопросы
- Какие типовые функции анализа применимые к Grid-темам вы знаете?
- Поясните термины: экстент темы; проект; компоновка; атрибутивная таблица.
- Каковы особенности работы с Таблицей содержания Вида.
ЛАБОРАТОРНАЯ РАБОТА № 6
Тема: Применение информационно-картографического подхода к анализу связей природных явлений
Продолжительность 4 часа
Задание: Выполните пространственный анализ закономерностей между заданными преподавателем факторами информационным методом.
Ход работы:
Определите моделируемую систему, выделив компонент и факторы, определяющие состояние выбранного компонента.
Подготовьте исходные данные, для этого: постройте с помощью ГИС ArcView 3.1 цифровые карты компонента и факторов. Далее необходимо разбить на зоны все карты так, чтобы и факторы и компоненты были разбиты на несколько интервалов.
С помощью функции ГИС «Гистограмма по зонам» подготовьте данные для таблиц частот наблюдений для каждого однофакторного канала связи. Количество строк в каждой таблице равно количеству интервалов фактора, а количество столбцов равно количеству интервалов компонента.1
С помощью компьютерной программы INFORM вычислите основные характеристики информационного анализа для каждой однофакторной связи «фактор Вi - компонент А».
Выполните анализ полученных данных, при этом постарайтесь выяснить, в какой степени факторы влияют на компонент ПТК; где эта связь крепче или, наоборот, слабее; если каждому состоянию компонента соответствует определенный интервал значений факторов, то какой именно; каков объем экологической ниши, занимаемый каждым состоянием компонента в многомерном пространстве факторов; какие именно показатели определяют локализацию тех или иных состояний компонента на исследуемой территории.
- на основе коэффициентов информативности постройте графики плотности связи, откладывая по оси ординат значения коэффициентов информативности фактора, а по оси абсцисс значения фактора.
- Сопоставляя значения коэффициентов эффективности передачи информации от факторов к компоненту в однофакторных каналах связи «компонент В – фактор Аi» определите: а) ведущий фактор в определении пространственного поведения компонента; б) порядок значимости факторов в поведении компонента.
- Постройте карту плотности связи для ведущего фактора.
- Выявите с помощью коэффициентов информативности и коэффициентов связи: а) участки наибольшей и минимальной информативности факторов о компоненте; б) взаимоспецифичные состояния (С(ai|bj)>1).
На основании коэффициентов связи определите экологические амплитуды типологических единиц компонента по каждому фактору. Положение коэффициентов связи ( знаков «+» для С(ai|bj)>1) прямо указывает на пределы крайних значений фактора, при которых встречается то или иное состояние компонента, т. е. характеризует амплитуду устойчивости данного варианта компонента по отношению к рассматриваемому фактору. Разновидностью экологической амплитуды является относительная мера устойчивости по отношению к тому или иному фактору. Если для каждого фактора принять разность крайних значений, наблюдаемых на исследуемой территории за условную единицу, то экологическая амплитуда по каждому фактору для каждого варианта компонента может быть выражена как доля рассматриваемого интервала крайних значений фактора. Очевидно, что, чем больше доля в каждом конкретном случае, тем больше устойчивость того или иного варианта компонента к изменениям данного фактора.
Таким образом, экологическая амплитуда по каждому фактору для каждого варианта компонента может выражаться как в реальных значениях данного фактора, так и как доля от условной единицы. Применение объективных экологических амплитуд, выраженных в долях единицы, значительно расширяет возможности анализа и позволяет получить ряд количественно подкрепленных выводов.
Логично предположить, что чем больше средние значения экологической амплитуды по рассматриваемому фактору, тем больше приспособленность данной группы типологических единиц компонента к изменениям фактора; чем меньше среднее значение экологической амплитуды по фактору, тем больше значимость этого показателя в пространственном поведении данной группы типологических единиц компонента.
Информационно-картографический анализ открывает широкие возможности для объективного изучения пространственных связей природных явлений.
Вопросы для самопроверки
- Как на основе информационного анализа сделать прогноз компонента по заданной совокупности значений факторов?
- Какова точность информационного анализа?
- Перечислите преимущества и недостатки информационного анализа.
ЛАБОРАТОРНАЯ РАБОТА № 8
Тема: Применение кластерного анализа в экологических исследованиях с использованием пакета прикладных программ "STATISTICA"
Продолжительность 4 часа
Основная цель работы: изучение особенностей применения многомерных методов анализа (кластерный) в экологических исследованиях.
Теоретическая часть:
Кластерный анализ относится к многомерным методам математического анализа. Его используют, когда необходимо провести классификацию объектов.
Общей задачей классификации является упорядочение элементов относительно друг друга по их взаимоотношениям в выборке. Любая классификация вообще, и кластер-анализ в частности, обеспечивает уменьшение размерности изучаемого явления [1].
Задача кластерного анализа заключается в разбиении множества объектов I на некоторое количество m кластеров (подмножеств), при этом необходимо, чтобы элементы объектов принадлежащие одному и тому же кластеру были сходными, а принадлежащие разным кластерам были разнородными (несходными).
Допустим, что у нас имеется несколько стран, каждая из которых характеризуется валовым национальным продуктом на душу населения (С1), личным потреблением на душу населения (С2), душевым потреблением электроэнергии (С3) и т.д., тогда подмножество Х1 (вектор измерений) представляет собой набор перечисленных характеристик для первой страны, Х2 для второй, Х3 для третьей. Задача заключается в том, чтобы разбить страны по уровню развития.
Решением задачи кластерного анализа является разбиение некоторого количества объектов с помощью определенного критерия (метрики). Этот критерий может представлять собой некоторый функционал, который так группирует объекты (выделяет кластеры), чтобы попавшие в него переменные были наиболее сходными, соответственно, различные подмножества (кластеры) - наиболее разнородными. Этот функционал часто называют целевой функцией или метрикой (например, в качестве целевой функции можно взять внутригрупповую сумму квадратов отклонений).
СТРАНА_1 СТРАНА_2 СТРАНА_3 СТРАНА_4 СТРАНА_5 СТРАНА_6 СТРАНА_7 СТРАНА_8 СТРАНА_9 СТРАНА10
С1 104,000 694,000 360,000 1563,000 2117,000 800,000 70,000 72,000 946,000 180,0000
С2 40,000 696,000 393,000 1552,000 2782,000 872,000 203,000 68,000 1048,000 208,0000
С3 72,000 725,000 422,000 1625,000 2927,000 676,000 296,000 80,000 1102,000 181,0000
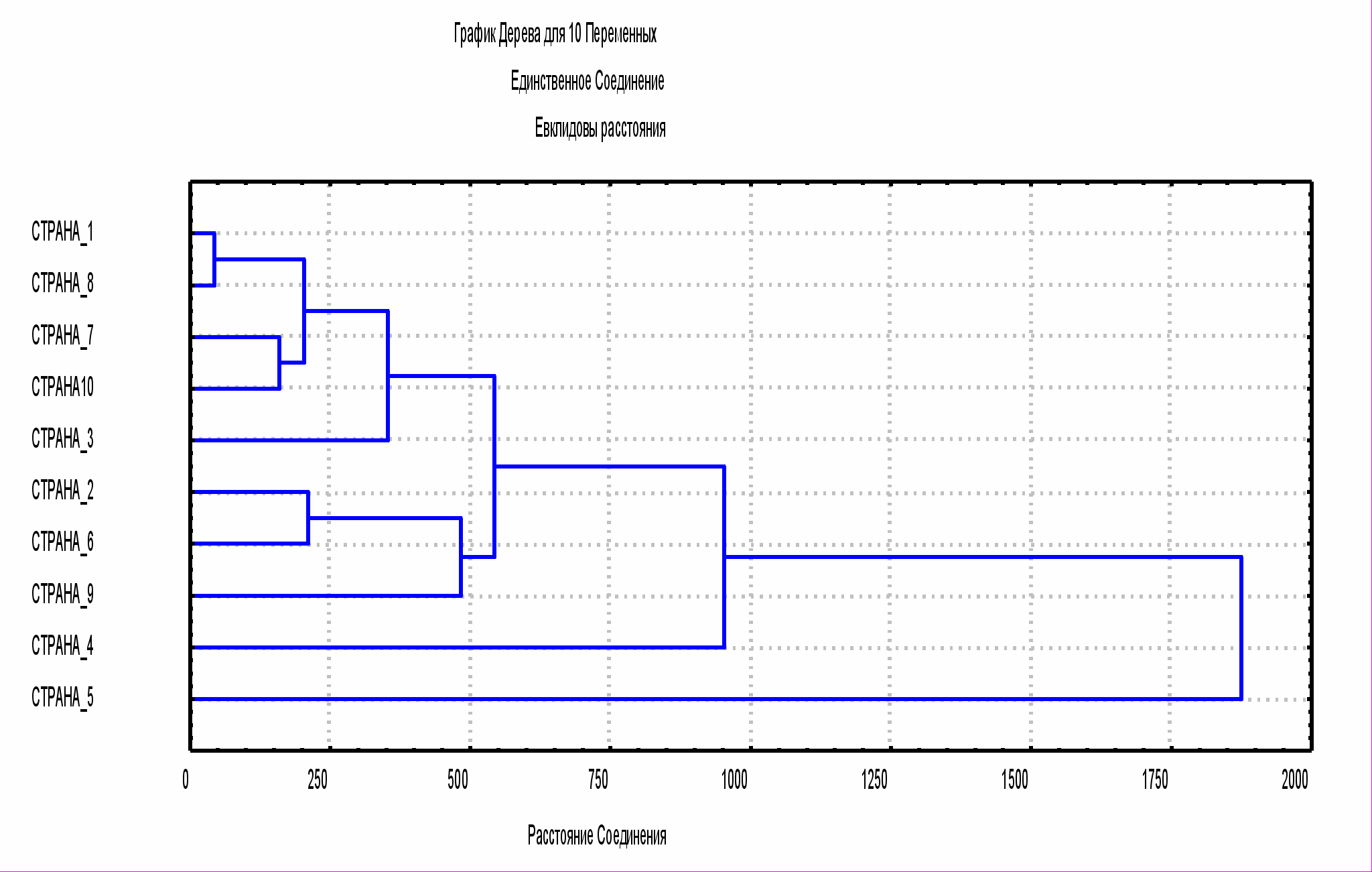
рис.1 Классификация стран по уровню развития
Методологические особенности кластерного анализа сводятся к выявлению единой меры, охватывающих ряд исследуемых признаков, т.е. необходимо количественно определить понятия сходства и разнородности. Задачу можно считать решенной, если i-й и j-й объекты попадали в один и тот же кластер всякий раз, когда расстояние (отдаленность) между соответствующими точками Хi и Хj было бы достаточно малым, и наобарот, попадали в разные кластеры, если бы расстояние между точками Хi и Хj было бы, "достаточно большим". Для достижения этой цели, оперируют понятием расстояния, как некой функцией между точками Хi и Хj в пространстве, с абстрактных позиций. Эти признаки объединяются с помощью метрики в один количественный показатель сходства группируемых объектов.
Классификация будет наиболее точно отображать реальность в том случае, когда вид метрики наилучшим образом соответствует форме отношений между свойствами. Выделяются два типа отношений: линейные и нелинейные. Формулировка гипотезы о типе отношений – наиболее сложная задача.
Например, в работе [2] при изучении миграции и перераспределения химических элементов в ландшафтном пространстве в качестве таких отношений выделялось подобие в распределении химических элементов. Поэтому при введении метрики необходимо избавиться от абсолютных значений. Наиболее простой способ для этого – стандартизация данных каждой переменной делением отклонения от среднего на среднеквадратическое отклонение соответствующей переменной. При классификации эксперименты проводились с четырьмя видами метрик:
1) метрика Эвклида:
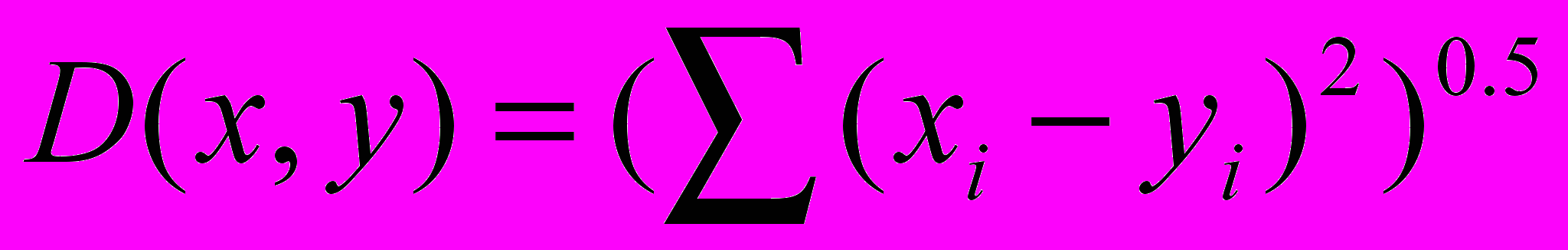 , где xi, yi – значения сравниваемых переменных в образце почвы i; 2) квадратическая метрика Эвклида:
, где xi, yi – значения сравниваемых переменных в образце почвы i; 2) квадратическая метрика Эвклида: 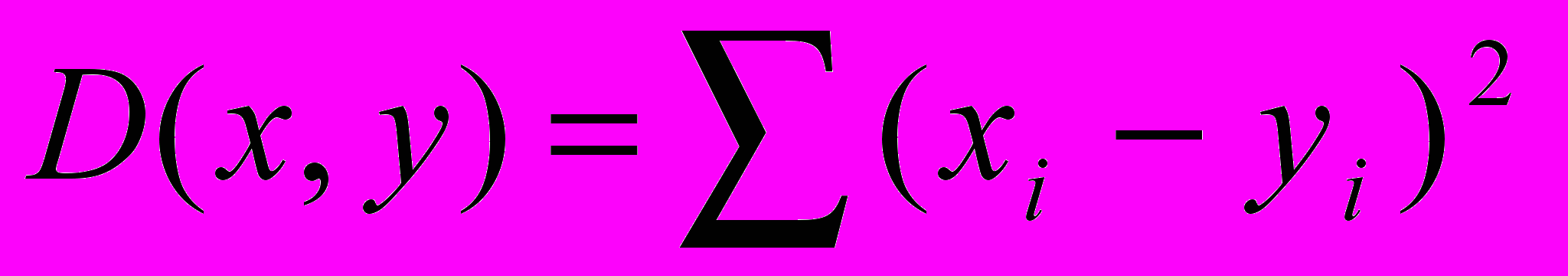 ; метрика Миньковского:
; метрика Миньковского: 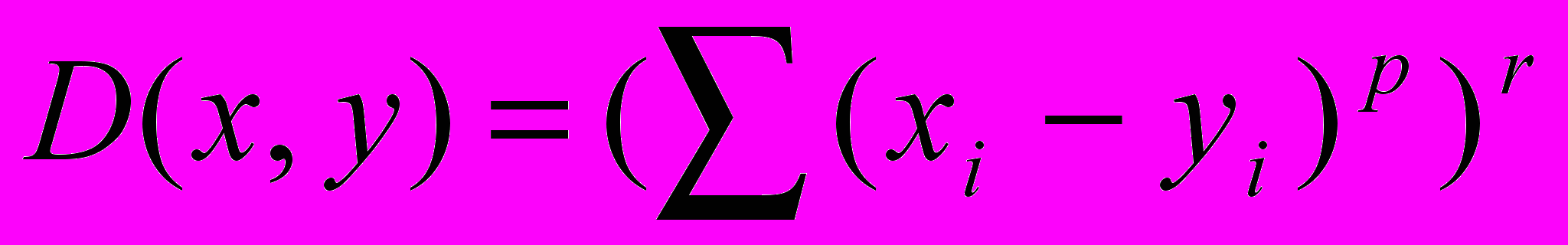 при r=1; 4) метрика Пирсона:
при r=1; 4) метрика Пирсона: 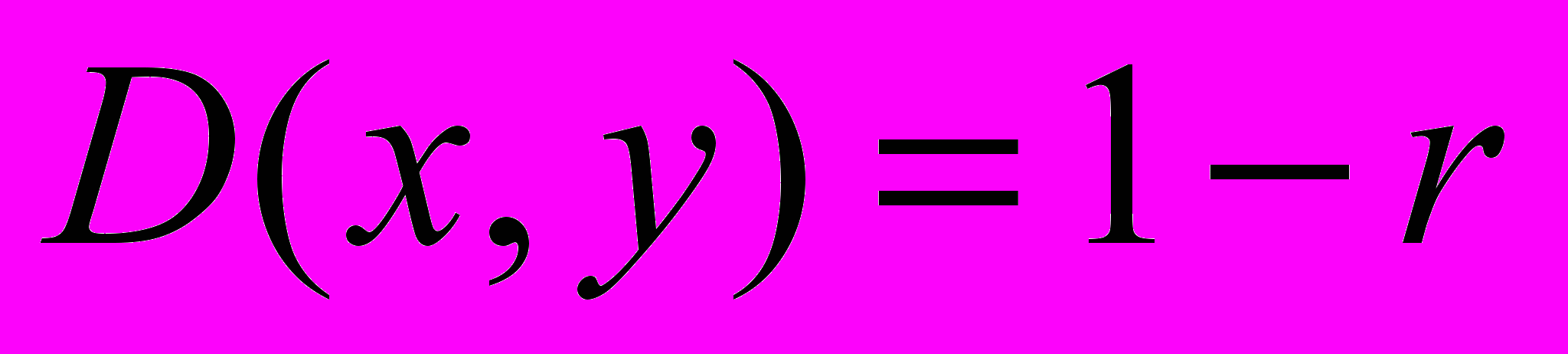 , где r – коэффициент корреляции.
, где r – коэффициент корреляции.Самих методов классификации существует несколько (метод ближайшего соседа, дальнего соседа, взвешенных и невзвешенных центроидов и т.д.)
На основе сравнения результатов разных классификаций выбирается та из них, которая наилучшим образом соответствует некоторым критериям оптимальности.
Результаты кластеризации представляются графически в виде дендограммы или диаграммы-дерева.
В диаграмме-дереве объекты располагаются вертикально слева, а результаты кластеризации справа. Значения расстояний или сходства изображаются на горизонтальной прямой поверх дендограммы.
На рис. 1 показана диаграмма-дерево для примера со странами, описанного выше. Из диаграммы-дерева видно, что наиболее близки по уровню жизни страна_1 и страна_8, страна_7 и страна_10, а также страна_2 и страна_6. Вид дендограммы зависит от выбора меры сходства или расстояния между объектом и кластером и метода кластеризации.