
Н. В. Симкин мультиплексируемая шина графической системы на базе
| Вид материала | Документы |
- Урок №1-2 по теме Архитектура компьютера. Магистраль: шина данных, шина адреса и шина, 61.5kb.
- Nokian Hakkapeliitta 7 (шипованная шина), 927.09kb.
- 1scsi (Small Computer System Interface), 197.4kb.
- 1. Графический интерфейс Большая часть манипуляций с объектами в графической оболочке, 99.42kb.
- Получить схему программы (данных), которые необходимо нарисовать средствами системы, 929.97kb.
- Учебное пособие по курсу «Русский язык и культура речи» для отделения «Международный, 2253.47kb.
- 1. Кодирование графической информации Пространственная дискретизация, 53.25kb.
- Оформление результатов проектирования курсовой проект, 64.91kb.
- Учебно-методический комплекс дисциплины: «Геоинформационные и земельно-информационные, 1019.33kb.
- Учебно-методический комплекс дисциплины: «Геоинформационные и земельно-информационные, 1021.73kb.
Вестник Брянского государственного технического университета. 2009. № 2(22)
УДК 621.38.068(03)
Н.В.Симкин
МУЛЬТИПЛЕКСИРУЕМАЯ ШИНА ГРАФИЧЕСКОЙ СИСТЕМЫ НА БАЗЕ
ПРОГРАММИРУЕМОЙ ЛОГИЧЕСКОЙ ИНТЕГРАЛЬНОЙ СХЕМЫ
VIRTEX-II PRO
Изложены результаты исследований, выполненных автором, по разработке архитектуры мультиплексируемой шины, которая работает совместно с локальной процессорной шиной PLB встроенного процессорного ядра PowerPC405 в FPGA Virtex-II Pro и дополняет ее функциональные возможности.
Ключевые слова: архитектура, встроенный процессор, мультиплексируемая шина, графическая система, PowerPC, Virtex-II Pro.
В исследуемых многофункциональных индикаторах (МФИ) используются архитектура и программное обеспечение графической системы на базе локальной процессорной шины PLB. Так как шина PLB имеет разделяемую архитектуру [1], то процессор и контроллер LCD, подключенные к шине PLB, могут обращаться к блокам памяти Sync RAM 1 и Sync RAM 2 только последовательно. Экспериментальные исследования данного варианта архитектуры графической системы показали ее малую производительность[2]. Для повышения производительности графической системы необходимо, чтобы модификация процессором содержимого блока памяти Sync RAM 1 выполнялась параллельно со считыванием данных контроллером LCD из блока памяти Sync RAM 2. С этой целью были спроектированы мультиплексируемая шина Multiplexed bus и графический ускоритель 2d- accelerator. Схема графической системы МФИ на базе мультиплексируемой шины представлена на рис.1.
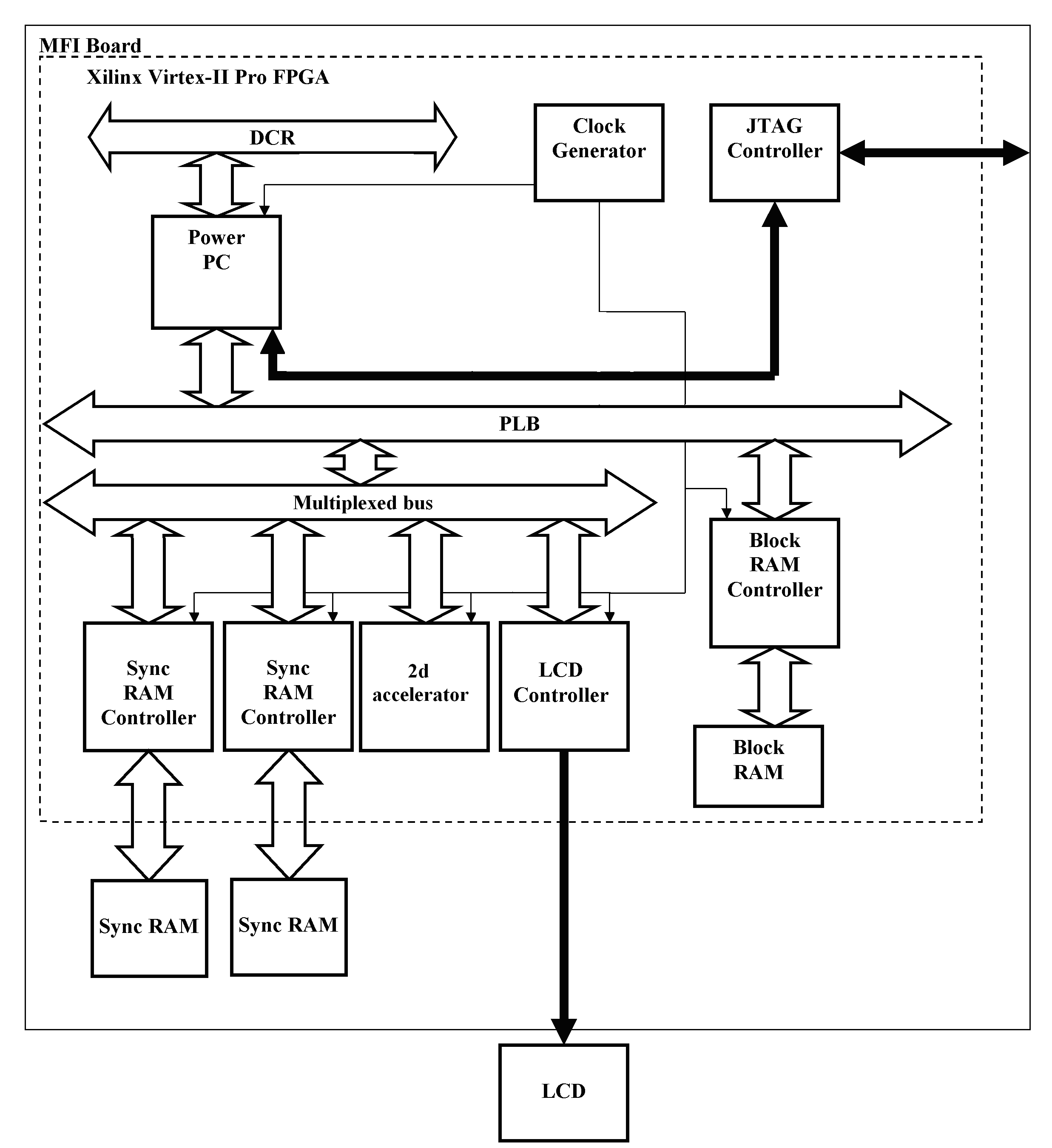
Рис. 1. Архитектура графической системы многофункционального
индикатора на базе мультиплексируемой шины
Обмен данными между устройствами, подключенными к мультиплексируемой шине, и процессором осуществляется через подчиненный порт шины PLB. Для мультиплексируемой шины этот порт шины PLB является мастером. Мультиплексируемая шина реализует необходимое подмножество функций шины PLB. Структура мультиплексируемой шины представлена на рис.2.
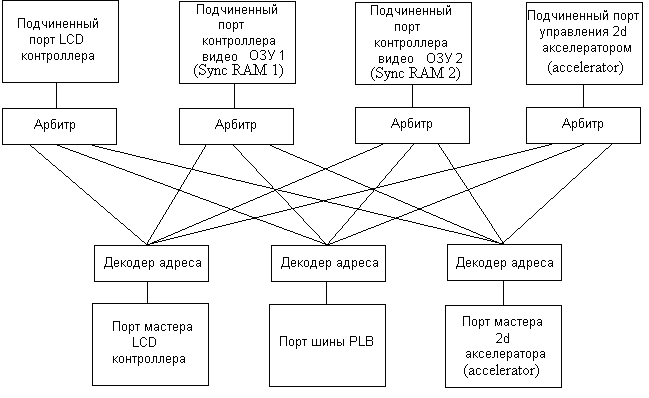
Рис. 2. Структура мультиплексируемой шины
Мультиплексируемая шина имеет следующие порты: подчиненный порт контроллера LCD, подчиненный порт контроллера Sync RAM 1 (видеоОЗУ1), подчиненный порт контроллера Sync RAM 2 (видеоОЗУ2), подчиненный порт управления 2d-акселератором, порт мастера контроллера LCD, порт мастера 2d-акселератора и порт шины PLB. Также в мультиплексируемую шину входят арбитры и декодеры адреса.
Мультиплексируемая шина совместно с шиной PLB выполняет функции арбитража и передачи данных. При этом мультиплексируемая шина реализует только функции, присущие ей, а функции PLB, которые разработаны специально для разделяемой шины, не используются. Однако устройства, подключаемые непосредственно к шине PLB, могут использовать весь набор функций, присущих шине PLB.
Архитектура мультиплексируемой шины предназначена для объединения элементов системы на кристалле и внешних устройств, входящих в систему, и включает в себя следующие основные функциональные модули: интерфейсы с подчиненными устройствами (slave_connect_interface), интерфейсы с устройствами мастеров (master_connect_interface), арбитры (arbiters), схемы коммутации. Она также определяет синхронизацию работы этих компонентов.
Иерархия модулей на языке Verilog, обеспечивающая логику работы мультиплексируемой шины, представлена на рис. 3.
Модуль верхнего уровня содержит объявления модулей интерфейсов с подчиненными устройствами, устройствами мастеров и объединяет эти устройства, подключенные к нему.
В модуле верхнего уровня объявляется столько модулей интерфейсов с подчиненными устройствами и модулей интерфейсов с мастерами, сколько необходимо в системе. Все эти модули связываются по принципу «каждый с каждым». В рассматриваемой графической системе имеется три мастера и четыре подчиненных устройства. В качестве подчиненных выступают два контроллера видеоОЗУ, порт управления контроллером LCD и порт управления 2d-акселератором. В качестве мастеров выступают интерфейс с шиной PLB, порты мастеров LCD-контроллера и 2d-акселератора.
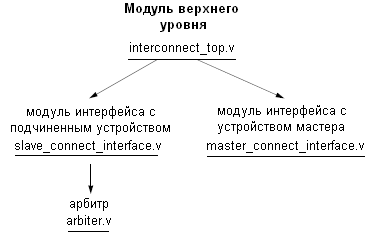
Рис. 3. Иерархия модулей на языке Verilog
Логика функционирования шины выглядит следующим образом. Мастер выставляет адрес и устанавливает в активное состояние сигналы запроса чтения или записи. Эти сигналы поступают на входы всех подчиненных устройств. При этом каждое подчиненное устройства имеет свой адрес и арбитра. Если какое либо из подчиненных устройств имеет такой же адрес, формируется сигнал запроса, который поступает на вход арбитра, а арбитр выдает или не выдает сигнал разрешения (grant). Когда этот сигнал поступает на вход мастера, цикл шины продолжается и осуществляется операция чтения или записи. Блок-схема модуля интерфейса мастера представлена на рис. 4.
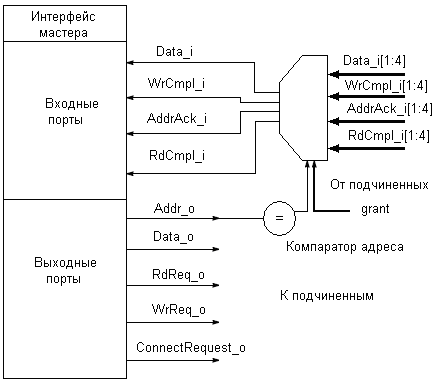
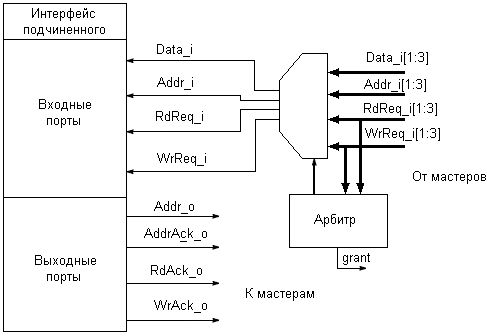
Рис. 4. Блок-схема модуля интерфейса мастера Рис. 5. Блок-схема модуля интерфейса подчиненного
Каждый модуль интерфейса мастера имеет четыре порта с подчиненными устройствами, так чтобы каждый подчиненный мог получать (передавать) данные от каждого мастера. Мультиплексор служит для того, чтобы мастер получал данные от какого-либо конкретного подчиненного. Логика работы мультиплексора определяется адресом, выставляемым мастером и сигналами grant со стороны подчиненных. При декодировании адреса используются только старшие биты. Младшие биты адреса представляют собой адресное пространство подчиненного. Блок-схема модуля интерфейса подчиненного представлена на рис. 5.
Архитектура проекта и тестовая программа разрабатывались в системе автоматизированного проектирования и программирования электроники Xilinx ISE Design Suite на базе процессора PowerPC 405.
Первая группа функций тестовой программы осуществляет управление LCD-контроллером. В их задачу входит инициализация LCD-контроллера и запись адреса отображаемого видеобуфера в адресный регистр LCD-контроллера. Графическая система работает по принципу двойного буфера: когда сформирован кадр, происходит переключение видеобуферов, и следующий кадр формируется в другом буфере. Это выполняет функция FlipBuffer().
Вторая группа функций осуществляет управление 2d-акселератором. Они записывают в регистры 2d-акселератора соответствующие команды (очистки буфера, построения вектора).
Третья группа функций отвечает за построение графических примитивов. Особенность графических примитивов заключается в том, что они должны быть реализованы с использованием алгоритмов, обеспечивающих сглаживание. При этом реализованы следующие функции: построение линии и эллипса по алгоритму Wu (WuDrawLine, DrawEllipseAA, DrawFillEllipseAA), построение кривой Безье третьего порядка (DrawBezier), растеризация полигона со сглаженными краями (DrawPoligon), вывод растрового шрифта (PrintString) [3].
Результаты исследований представлены в таблице.
Таблица
Сравнительная характеристика производительности графических систем
| Функция | Время выполнения | |
| Система на базе мультиплексируемой шины | Система на базе шины PLB | |
| Вывод линии по алгоритму Брезенхема | 15 мкс | 67 мкс |
| Вывод символа с использованием таблицы шрифтов (8 х11) | 14 мкс | 51 мкс |
| Вывод строки из 30 символов | 400 мкс | 1,2 мс |
| Вывод не закрашенной окружности радиусом 30 пикселей | 41 мкс | 159 мкс |
| Вывод закрашенной окружности радиусом 30 пикселей | 680 мкс | 2,1 мс |
| Построение эллипса | 360 мкс | 1,1 мс |
Из таблицы следует, что время исполнения функций вычислительной системой МФИ на базе мультиплексируемой шины значительно уменьшилось, что дает возможность реализовывать функции вывода графических примитивов со сглаживанием, которые требуют больших вычислительных ресурсов, но изображения при этом создаются более естественными.
СПИСОК ЛИТЕРАТУРЫ
2. Симкин Н.В. Архитектура и программное обеспечение графической системы на базе ПЛИС Virtex-II Pro / Н.В. Симкин // Вестн. БГТУ. – 2009.-№1.-С. 58-64.
3. Чириков, С.В. Алгоритмы компьютерной графики / С.В. Чириков. – СПб: СПб ГИТМО(ТУ), 2001. – 120с.
Материал поступил в редколлегию 03.02.09.